Upload and publish data in NOMAD¶
In this tutorial, we follow the entire workflow for uploading and publishing research data in NOMAD via the graphical user interface (GUI). We use computational and experimental examples to demonstrate how raw files are transformed into structured, publishable datasets. By the end of the tutorial, we will publish the data in NOMAD and assign it a Digital Object Identifier (DOI).

What you will learn¶
In this tutorial, you will learn how to:
- Upload raw research data to NOMAD and organize it using uploads
- View the entries that NOMAD generates from your files and check their processing status
- Share uploads with collaborators and manage access permissions
- Publish uploads and understand the role of embargoes
- Group entries into datasets for curation and publication
- Publish datasets and assign a Digital Object Identifier (DOI)
Before you begin¶
This tutorial requires no prior experience with NOMAD.
Before starting, make sure you have the following:
-
NOMAD user account
In order to upload data into NOMAD, a user account is required. You can create an account by following the steps described in the overview page. -
Example files available on your local machine
This tutorial uses provided example data files for:
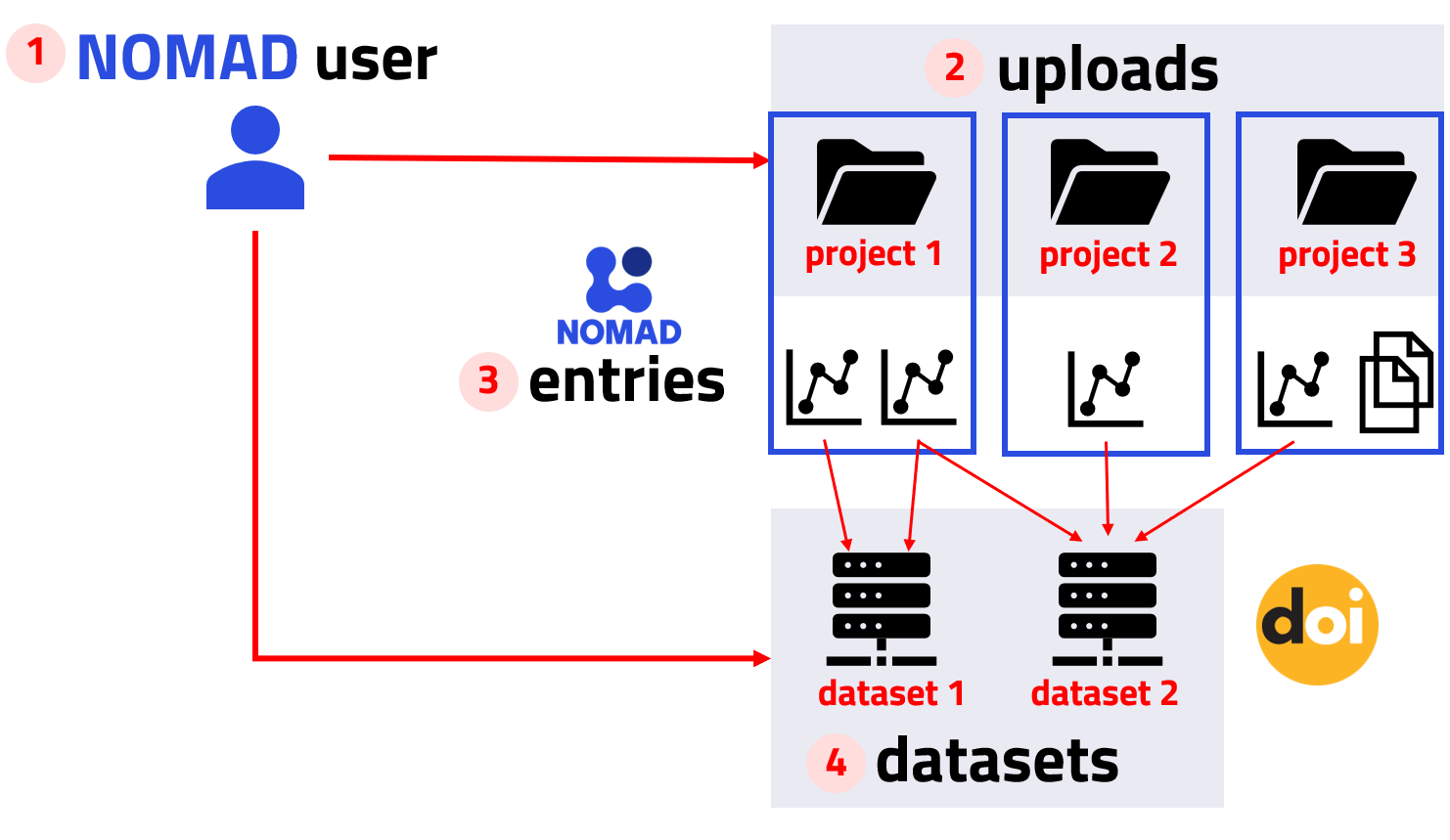
The key elements in NOMAD¶
To begin the journey from uploading raw files to publishing datasets with DOIs in NOMAD, you need to understand the key elements of this process in NOMAD, which are illustrated in the figure below.
-
All files and data created by users are organized in NOMAD as Uploads, which function as directories within the user’s account. You can create an upload for each project and structure it into nested folder directories for better organization.
Features of NOMAD Uploads
- Creation: Uploads are created and managed by users.
- Structure: Uploads are associated to a user account and are listed in the my uploads page in the GUI. They serve as containers for multiple files and entries, preserving their directory structure and metadata.
- Organization: Each upload can contain multiple files organized into directories.
- Sharing & Publishing: Entries and files can only be shared, transferred, or published as complete uploads.
-
Research data in the form of raw files are added to uploads. If NOMAD has a built-in parser for the file formats, it automatically processes the files and creates Entries. These entries represent structured data extracted from the raw files.
Features of NOMAD Entries
- Creation: Entries are automatically generated by NOMAD from uploaded raw files or instantiated schemas.
- Structure: Entries are distinct data entities that can be searched and viewed through dedicated pages in the NOMAD GUI.
- Organization: Entries belong to specific uploads and are linked to a raw file that NOMAD has recognized and parsed.
- Sharing & Publishing: Entries can be shared as part of an upload, and individual entries can be added to datasets, which can be published with a DOI.
-
Entries can be grouped into Datasets, which allow for better organization of related data. Once the dataset is complete, it can be published with a DOI, making the research data findable, accessible, interoperable, and reusable (FAIR).
Features of NOMAD Datasets
- Creation: Datasets are created and managed by users.
- Structure: Datasets are associated to a user account and are listed in the Your datasets page in the GUI. They serve as containers for curated and related data entries.
- Organization: Datasets contain entries from one or more uploads. An entry can belong to multiple datasets.
- Sharing & Publishing: Datasets are published independent of uploads and you can get a DOI for your datasets.
For more detailed explanation, you can refer to this page.
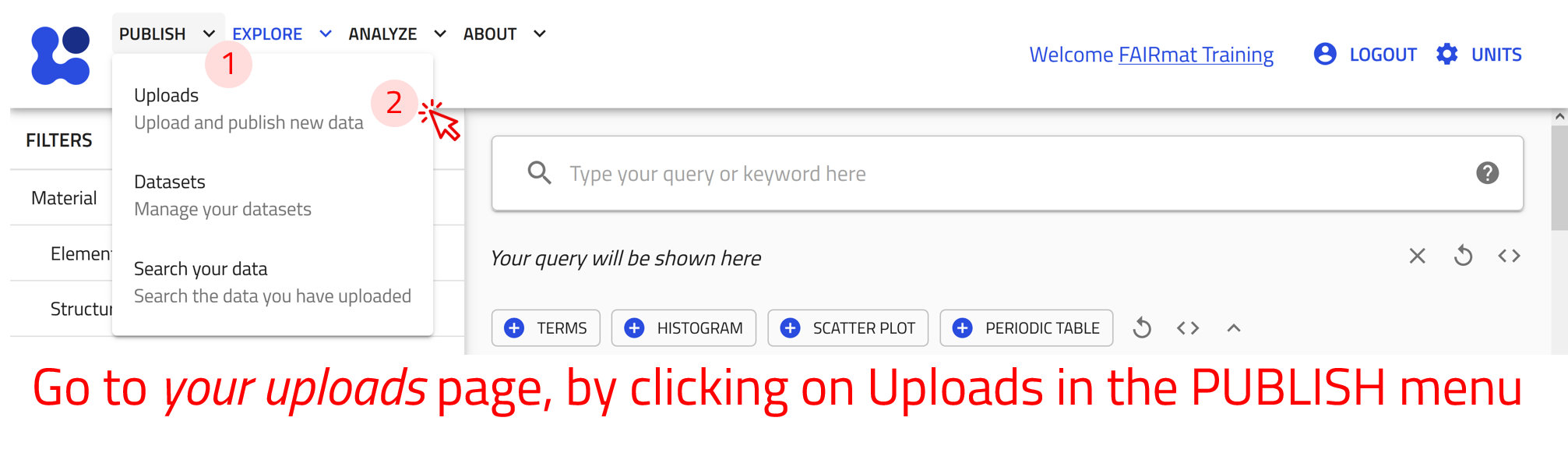
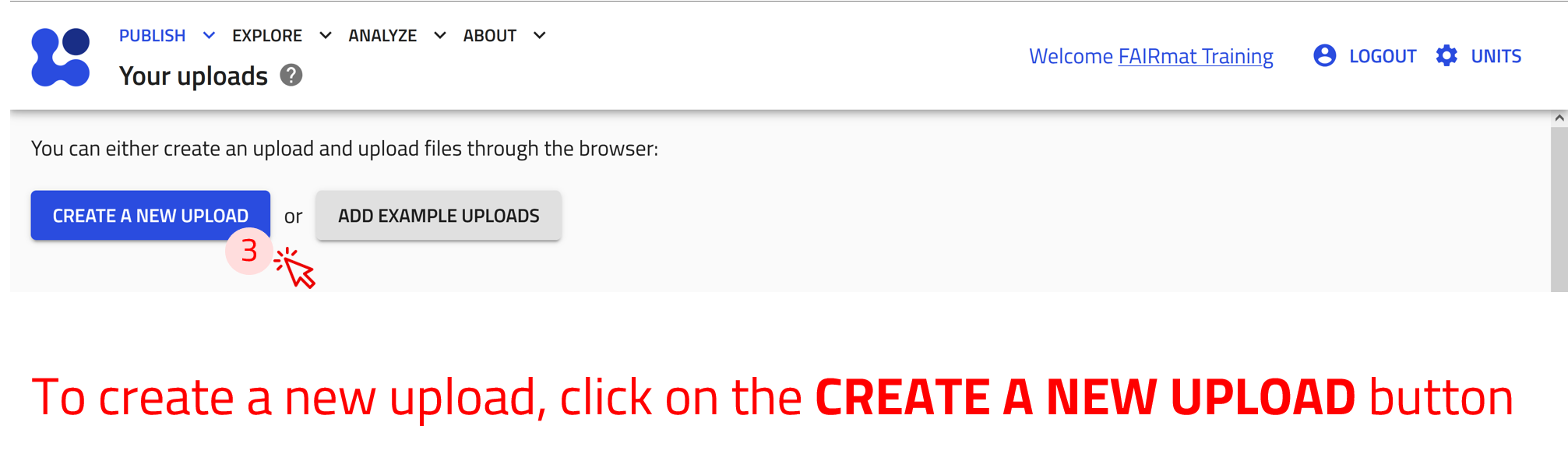
Create new upload¶
The uploads exist in the Your uploads page. Here you can view a list of all your uploads with their relevant information. You can also create new uploads or add an example upload prepared by others.
Use the arrow buttons ⬅️➡️ below to follow the steps for creating your first upload.
Two different views of the upload page
At the very top of the upload page, you can toggle between two different views for this page:
- Overview: This view includes all the tools needed to manage your upload, along with guided steps to start uploading your files to NOMAD. It will also show all the processed files (entries) that you will upload.
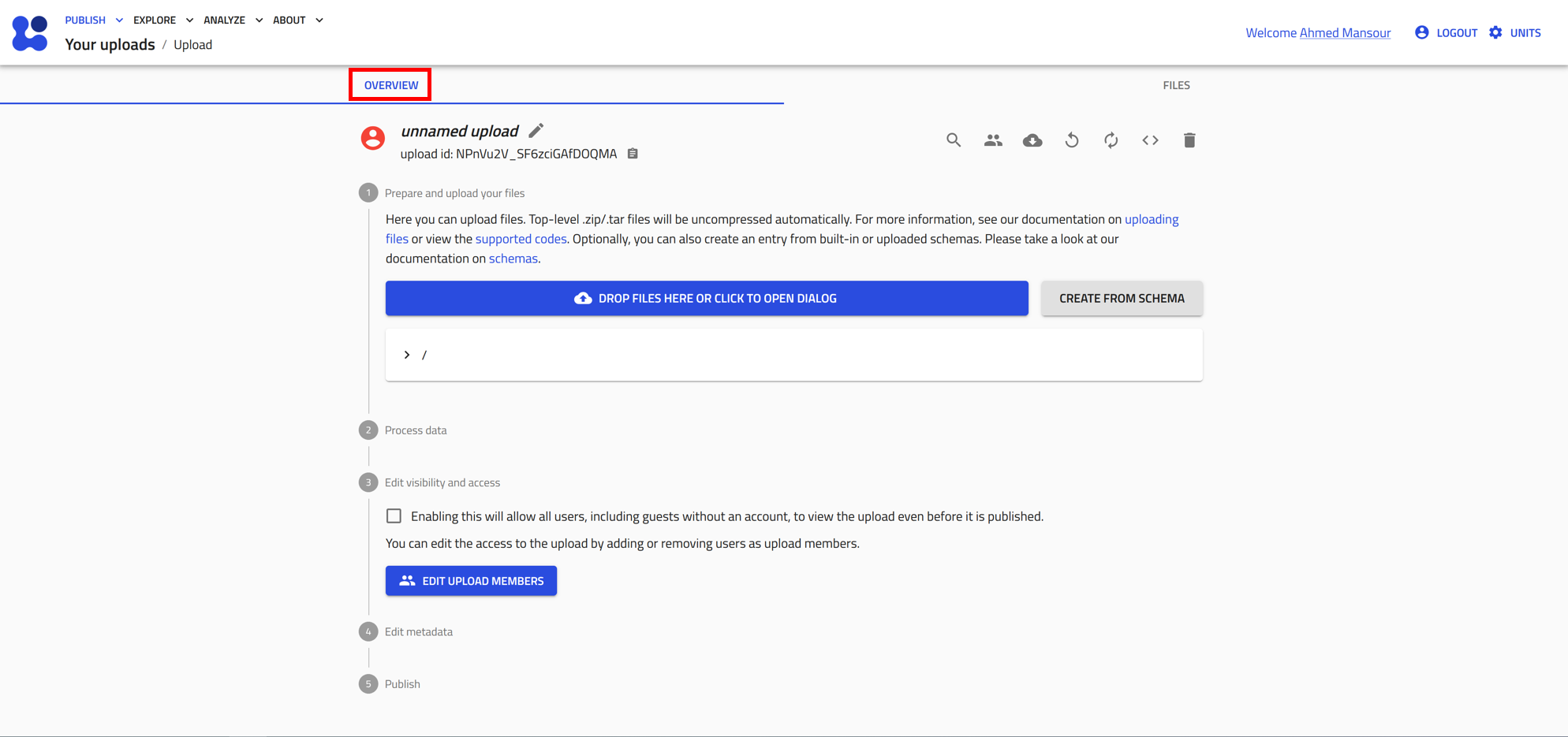
- Files: This view shows all the files included in the upload, whether they are raw files or processed files. You can also organize these files into folders as needed.
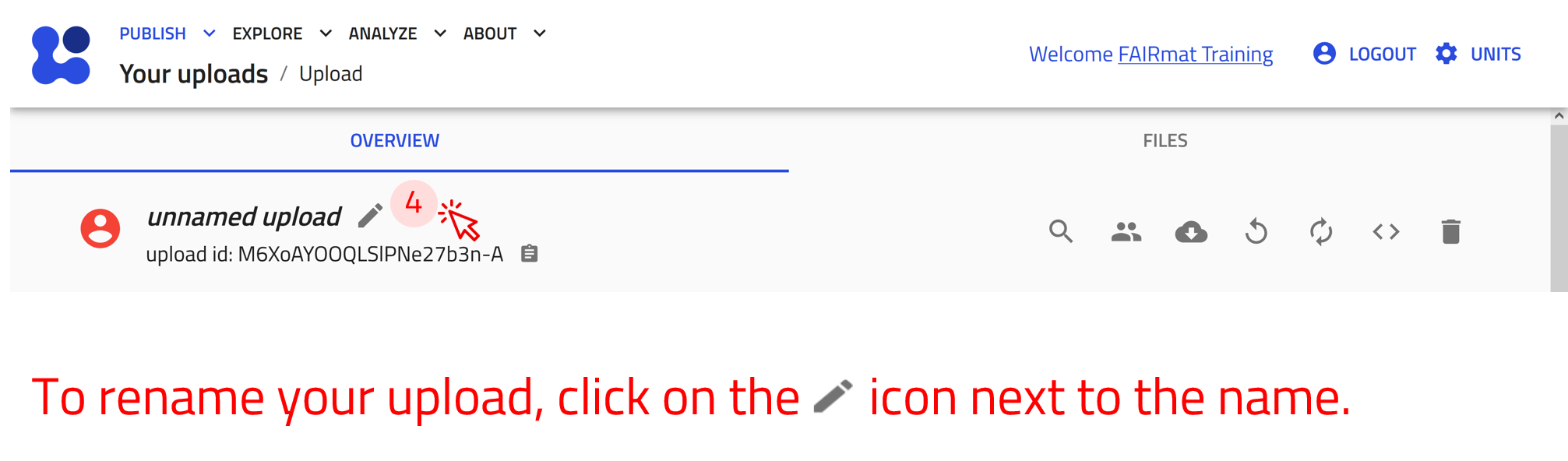
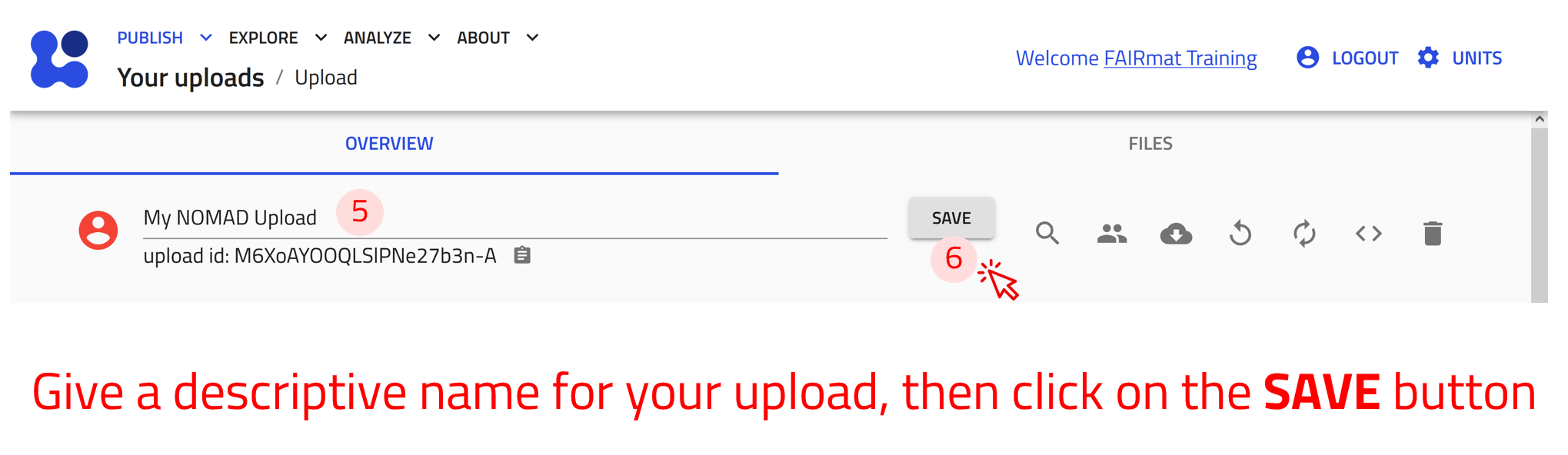
Icons on the upload overview
At the top of the OVERVIEW tab, you will find several icons that help you to manage your upload:

The name of the upload can be modified by clicking on the pen icon . The other icons are used as follows:
Manage members: Allows users to invite collaborators by assigning co-authors and reviewers roles.
Download files: Downloads all files present in the upload.
Reload: Reloads the uploads page.
Reprocess: Triggers the uploaded data to be processed again.
API: Displays a GET request url and corresponding JSON response demonstrating how to access the entries of the upload via the NOMAD API and the expected result, respectively.
Delete the upload: Deletes the upload permanently.
Components of the upload overview
The remainder of the uploads page is divided into five segments, each presenting a step in the uploading and publishing process:
1. Prepare and upload your files: displays the files and folder structure of the upload. You can add a README.md file to the root directory and its contents will be shown above this section.
2. Process data: shows the processed data and the generated entries in NOMAD.
3. Edit visibility and access: allows users to make the upload public or share it with specific users before publishing.
4. Edit author metadata: allows users to edit certain metadata fields from all entries recognized in the upload. This includes comments, where you can add as much extra information as you want, references, where you can add a URL to your upload (e.g., an article DOI), and datasets, where you can link the uploaded data to other uploads to define a larger-scale organizational structure (see Group entries into a dataset below.)
5. Publish: lets users publish data with or without an embargo (i.e., a waiting period before the data are publicly visible).
Share and publish uploads¶
Uploads in NOMAD can be shared or published. When an upload is shared or published, all entries and files contained within it are also shared or published.
What is the difference between sharing and publishing an Upload?
Sharing an upload allows you to grant access to colleagues or collaborators while working on it.
- This facilitates collaboration on projects or enables progress reviews during the project.
- You can invite individuals with either read/write access (coauthors) or read-only access (reviewers).
Publishing an upload makes it searchable, findable, and accessible on NOMAD for everyone.
- Once published, the upload becomes immutable, meaning its contents can no longer be modified.
- You also have the option to publish with an embargo period, temporarily restricting public access until the embargo expires.
A NOMAD upload can have four states based on sharing and publishing:
| Status | Icon | Description |
|---|---|---|
| Private | The upload is private and is visible to the uploader only. | |
| Shared | The upload is accessible to selected users but not publicly available. | |
| Published | The upload is publicly available to everyone. | |
| Visible | The upload is unpublished but accessible to everyone. |
You can manage upload sharing in the Edit upload members menu. To access it, click on ![]() available at the top of the upload page.
available at the top of the upload page.
Alternatively, you can click the EDIT UPLOAD MEMBERS button below the list of entries on your upload page.
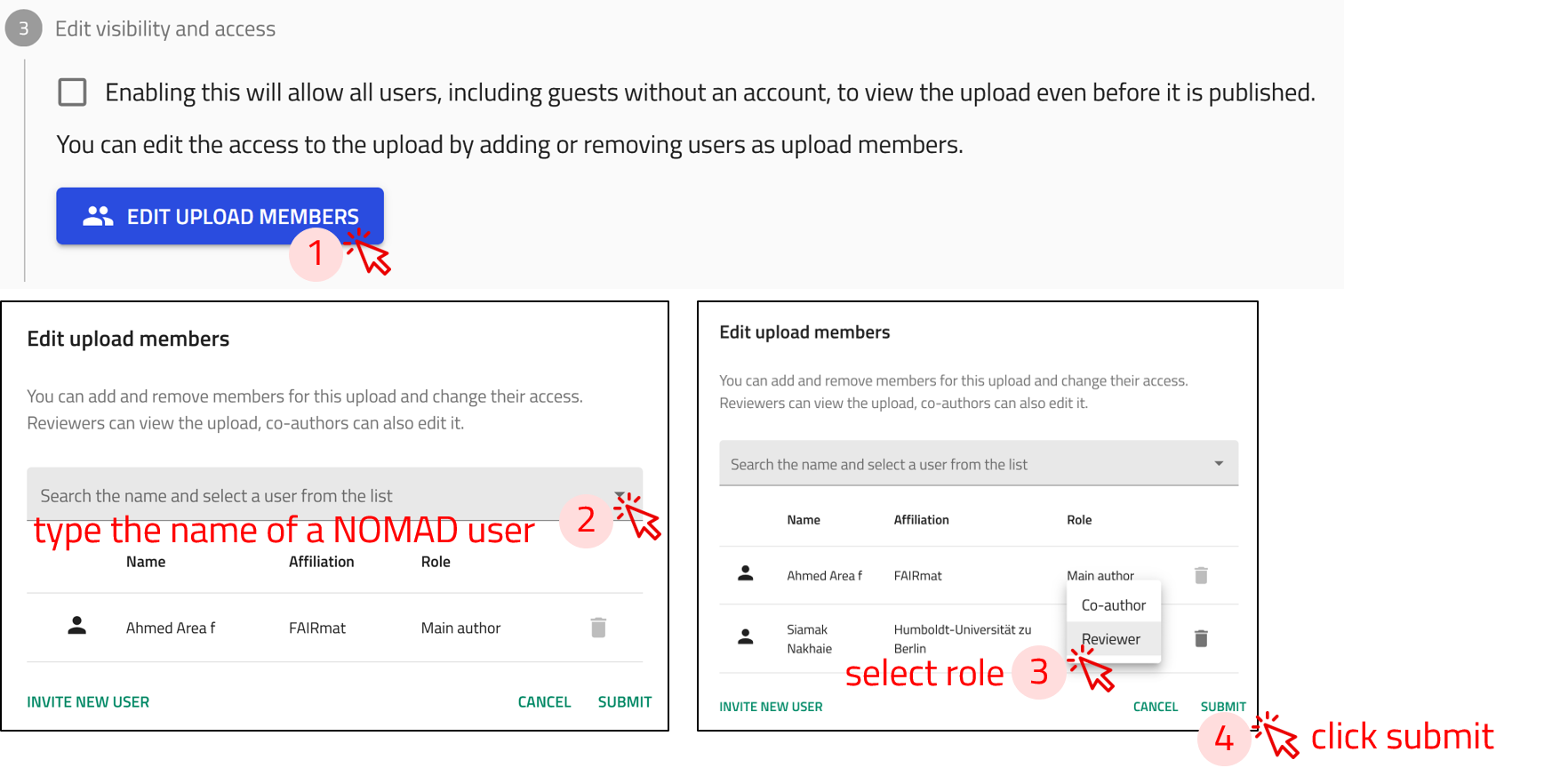
Share your upload
![]()
Step 1: Open the Edit upload members window, by clicking on the EDIT UPLOAD MEMBERS button.
Step 2: Start typing the name of the NOMAD user you want to share the upload with. A list of matching users will appear—select the correct name from the list.
Step 3: Assign a role to the user by selecting either Coauthor or Reviewer from the dropdown menu. - Coauthors can edit and add files to the upload. - Reviewers can only view the contents of the upload (no editing rights).
Step 4: Click on submit.
Make your upload visible to everyone
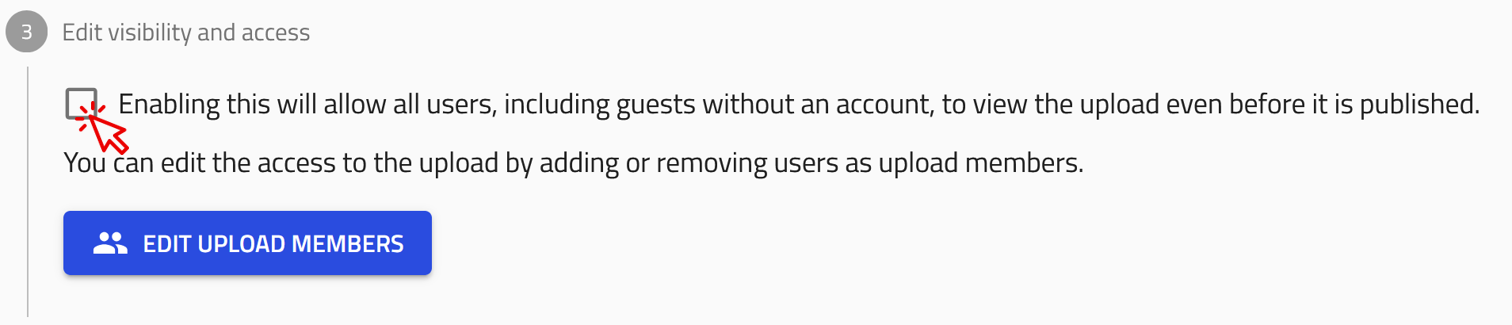
![]()
To make your upload visible to everyone on NOMAD, simply check the box in the Edit visibility and access section, located under the list of your entries.
This setting allows all users, including guests without an account, to view the upload even before it is published.
You can still modify the upload’s access settings and edit its contents while it remains visible.
Publish your upload
![]()
Once an upload is published, it cannot be deleted, and the files and entries cannot be changed
Step 1: Select an embargo period (if needed) from the dropdown menu, located in the publish section at the bottom of the upload page.
If you would like to publish immediately, select No embargo.
Step 2: Click on the PUBLISH button.
Step 3: A prompt for confirmation appears on the screen. Click on PUBLISH.
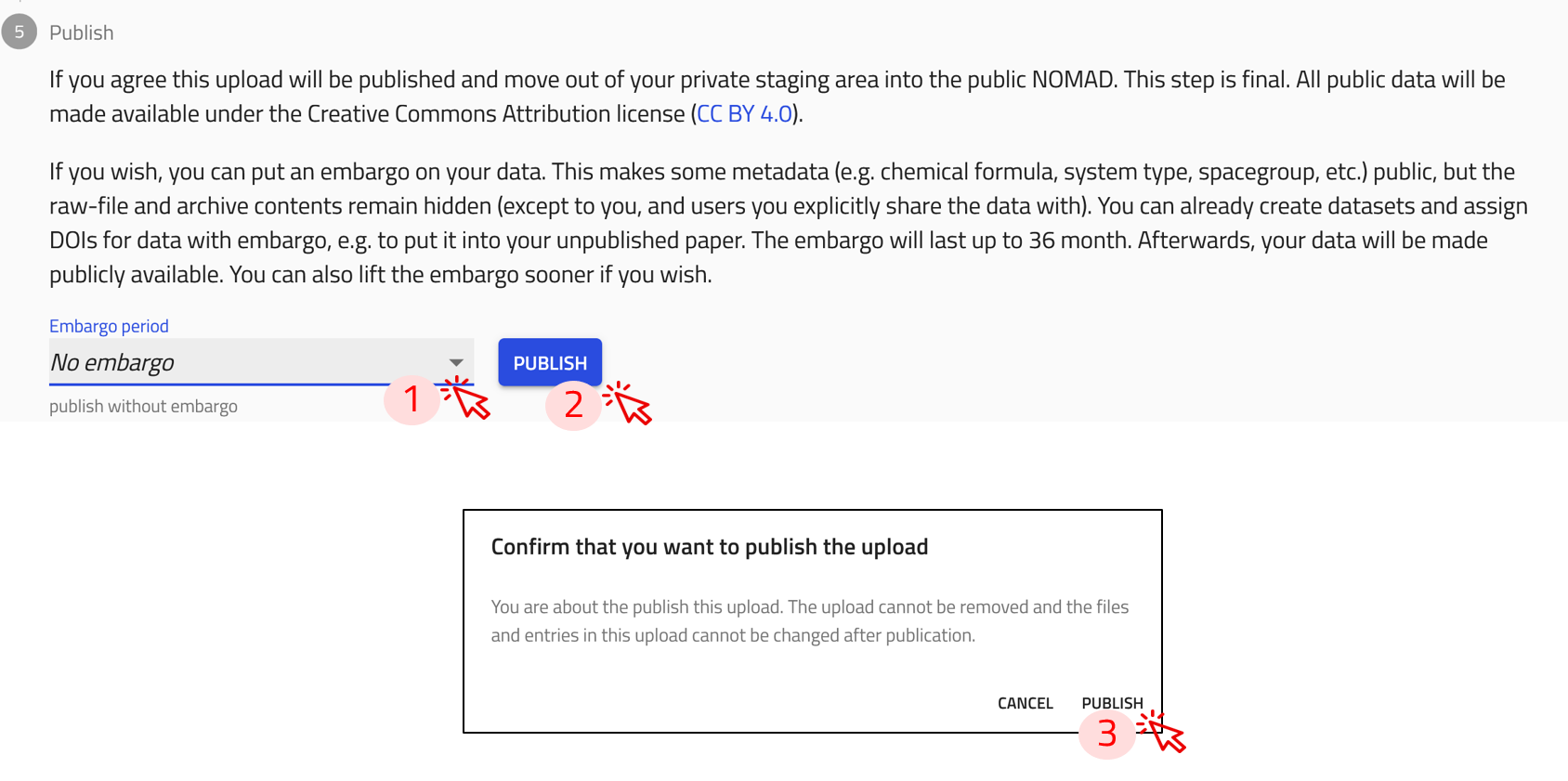
Having an embargo on your data means:
- Raw files and entries remain hidden, except to you and users you share the data with.
- Some metadata (e.g., chemical formula, system type, spacegroup) will be public.
- Embargoed entries can be added to datasets and be assigned DOIs.
- The embargo can be lifted earlier than the assigned duration by the user.
The following image shows an example of an embargoed upload and the option to lift the embargo by clicking the LIFT EMBARGO button.

Add files to an upload¶
Let's start adding files to your NOMAD upload. We will explore three different examples:
- Miscellaneous Files.
- Files of DFT calculation on Iron(III) Oxide.
- Files of x-ray photoelectron spectroscopy (XPS) measurement on polymers.
Files can be added to an upload individually, or you can group them into a compressed file in .zip or .tar formats.
Different ways and scenarios to upload files to NOMAD
In NOMAD, files can be uploaded in different ways, but whether they are processed into Entries or not depends on their format and NOMAD’s built-in parsers. Here’s how it works:
Files that are processed by NOMAD
-
These are files that are recognized by NOMAD, meaning that a built-in parser exists for the file you uploaded, the file will be processed according to a data schema.
-
It means that NOMAD reads the file, extracts data and organizes them based on the data schema which allows for generating visualizations, and analysis automations.
-
Raw files that are processed in NOMAD become Entries
-
This is common for simulation files since they follow standardized structures. Also a variety of experimental data organized in NeXus format
.nxsare recognized by NOMAD.
Files that are not processed by NOMAD
-
These are files that do not have a built-in parser, meaning NOMAD cannot automatically extract and structure their data.
-
They are still stored in NOMAD as part of your upload, and can be downloaded or shared, but they do not become entries in the database.
-
NOMAD allows you to preview common file formats that are not automatically parsed. This means you can view the contents of the file directly within the platform without having to download it. Examples include:
.txt,.csv,.pdf,.png,.jpg.
Upload miscellaneous files¶
Download the example files for this exercise
Download the folder, then uncompress it on your local machine at you preferred directory.
The folder contains files of the following formats: .zip, .pdf, .jpg, .txt, and .csv.
| file name | format | description |
|---|---|---|
| FAIRmat_graphics | .zip | Compressed file that contains several FAIRmat logos in .png format |
| JOSS_2023 | A publication of NOMAD in the Journal of Open Source Software | |
| Nature_2022 | A publication of FAIRmat in Nature journal | |
| P3HT_optical_absorption | .csv | Results of absorption measurement on P3HT from PerkinElmer spectrometer |
| note_properties_of_good_dopants | .txt | Notes recorded during a conference talk |
| experiment_polymer_doping | .jpg | A photograph of an experiment of preparing doped polymer solutions |
Note that these files will not create entries in NOMAD, because a built-in parser for them doesn't exist.
They will be stored in your upload and can be accessed and shared with your colleagues, however, they will not be searchable within NOMAD. In this case, NOMAD functions as a storage system, similar to a cloud drive.
You can add these files to your NOMAD upload. Do so by simply drag and drop the file or by opening the dialog to browse the files in your device.
Uploading images, pdf files, text files, and tabular data
Drag and drop
Start with uploading the file FAIRmat_graphics.zip. Let's use the drag and drop method as shown in the animation below.
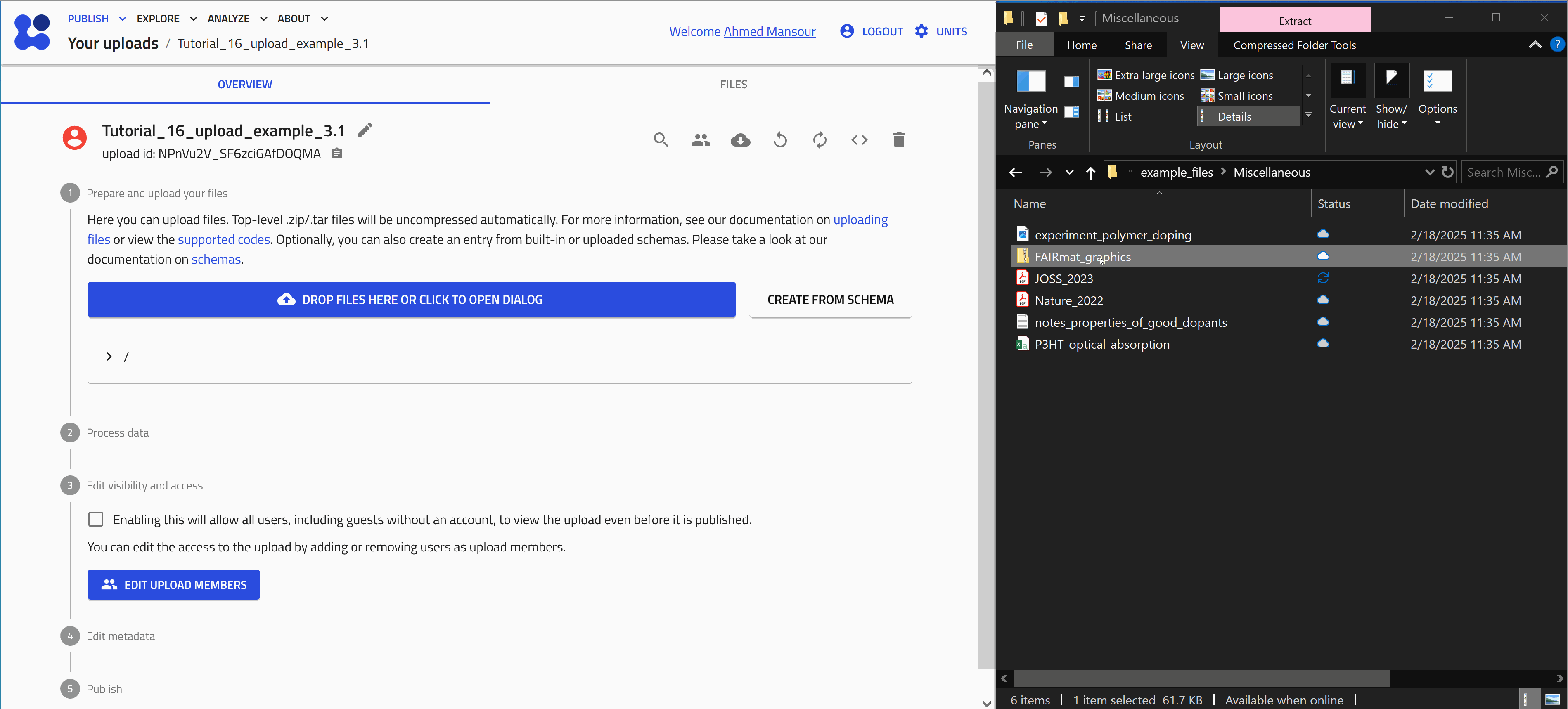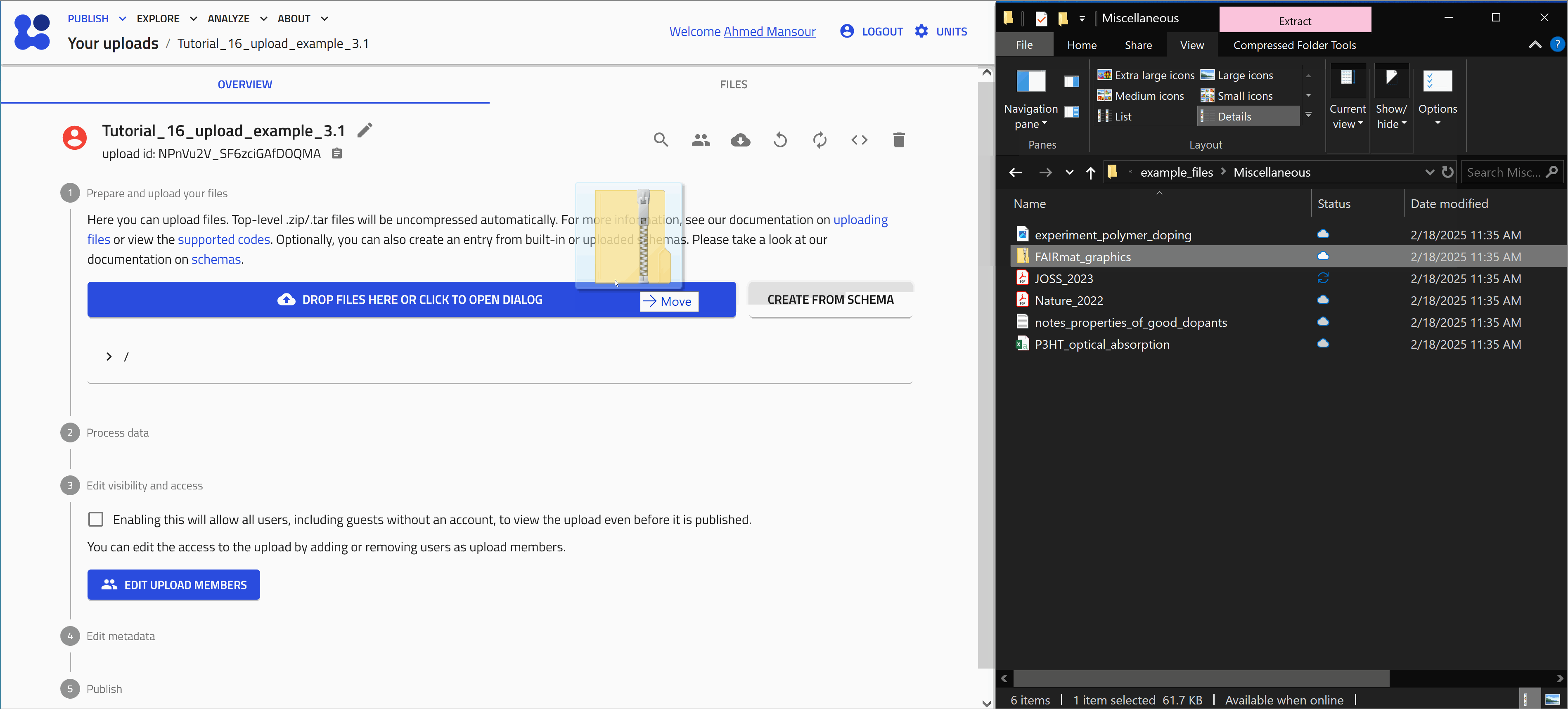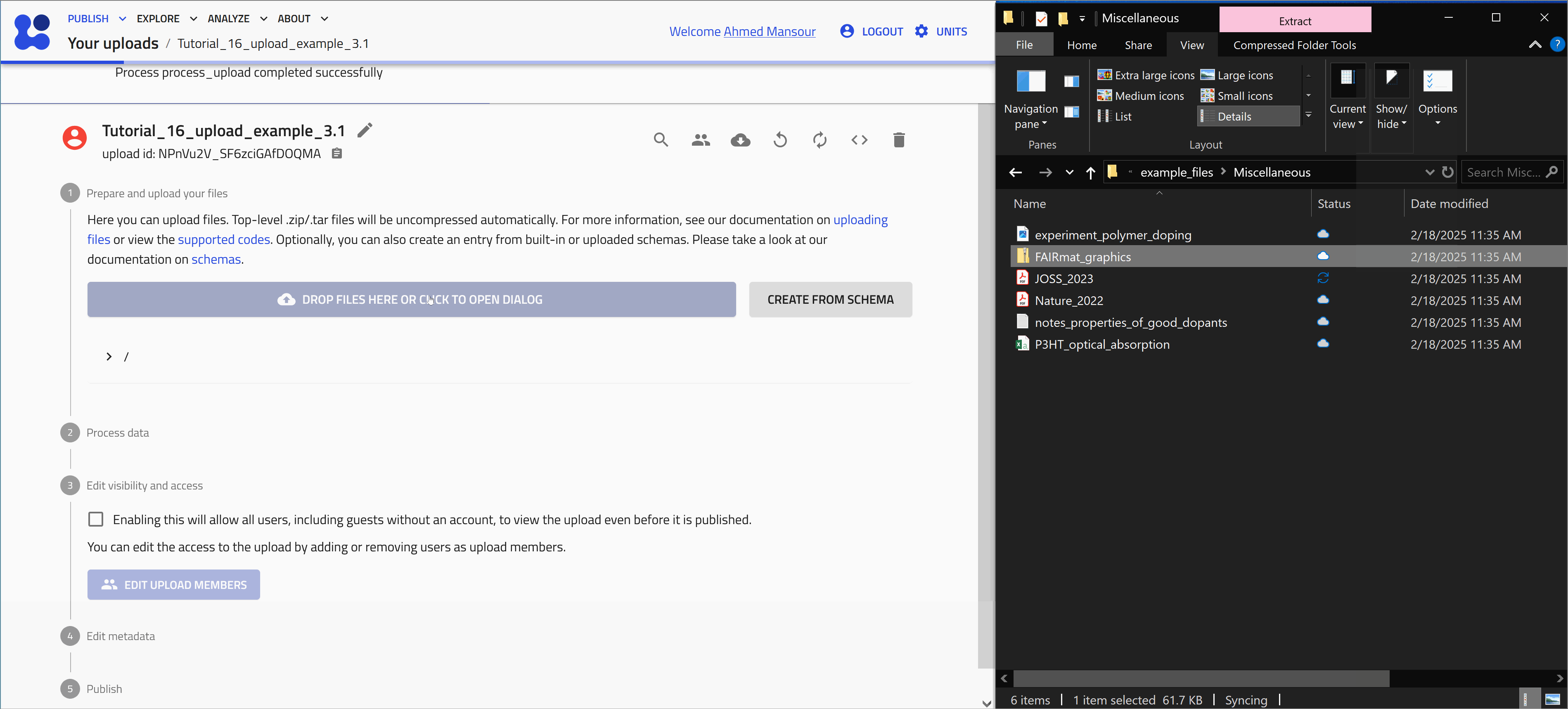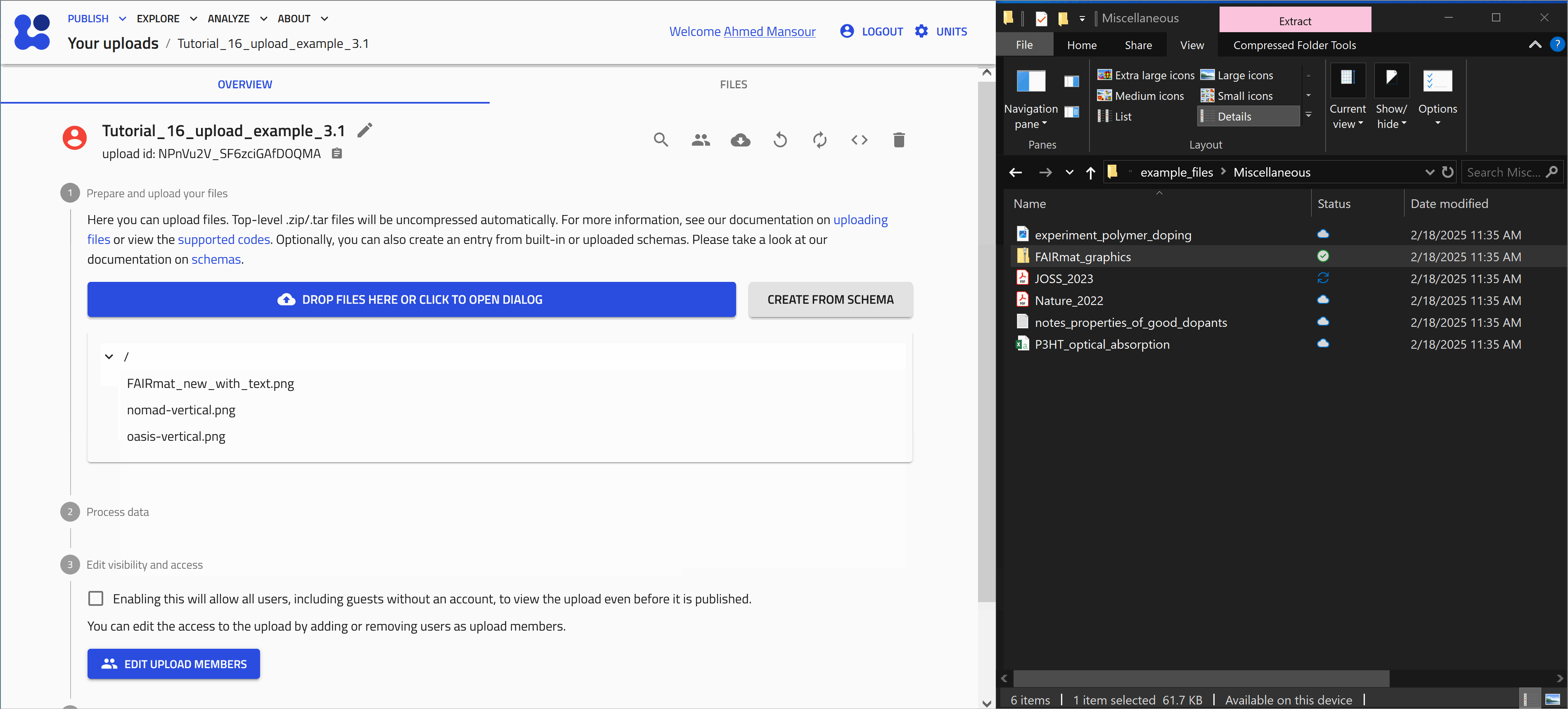
When a compressed file is uploaded to NOMAD, it will be extracted automatically and the included files will be added to your upload.
Open the file browser dialog
Upload the remaining files using the file browser dialog as shown in the animation below.
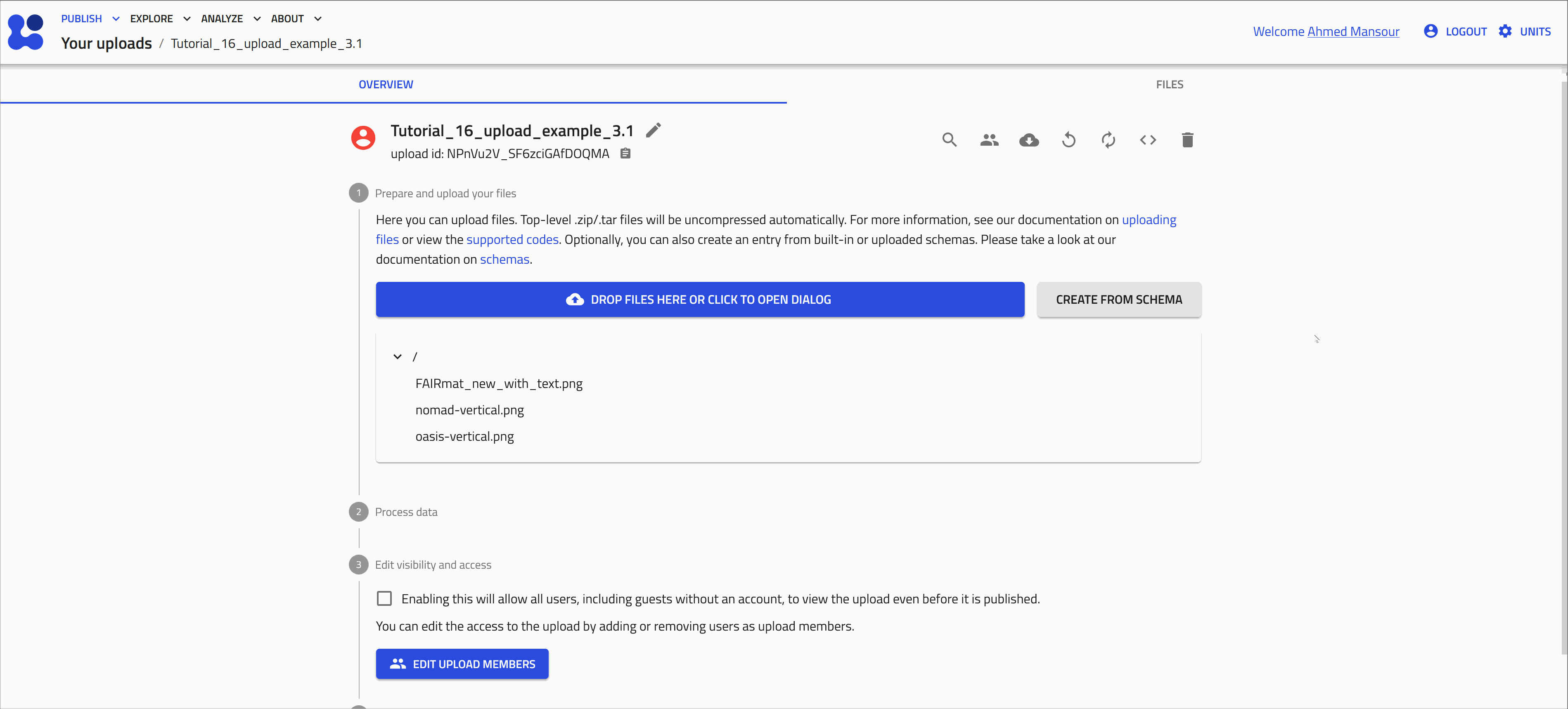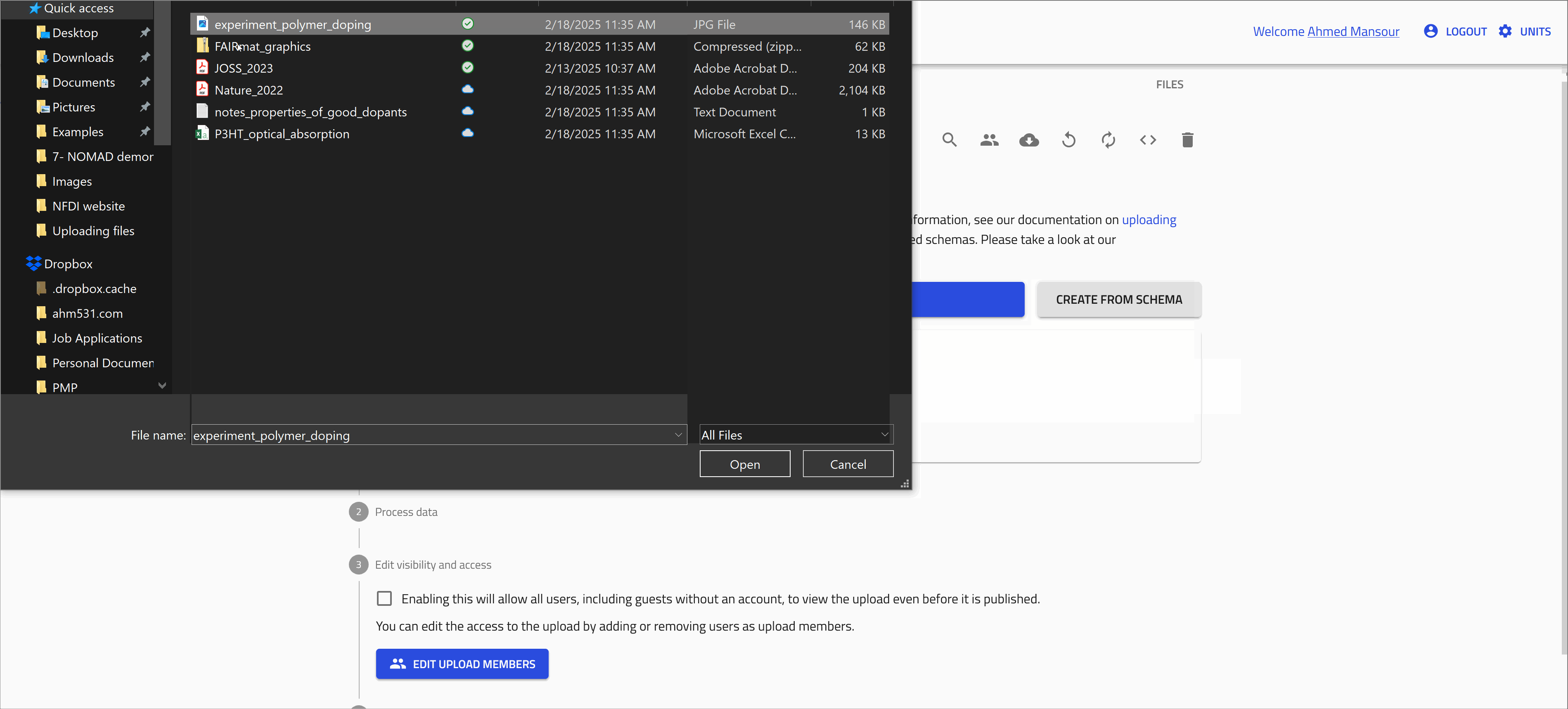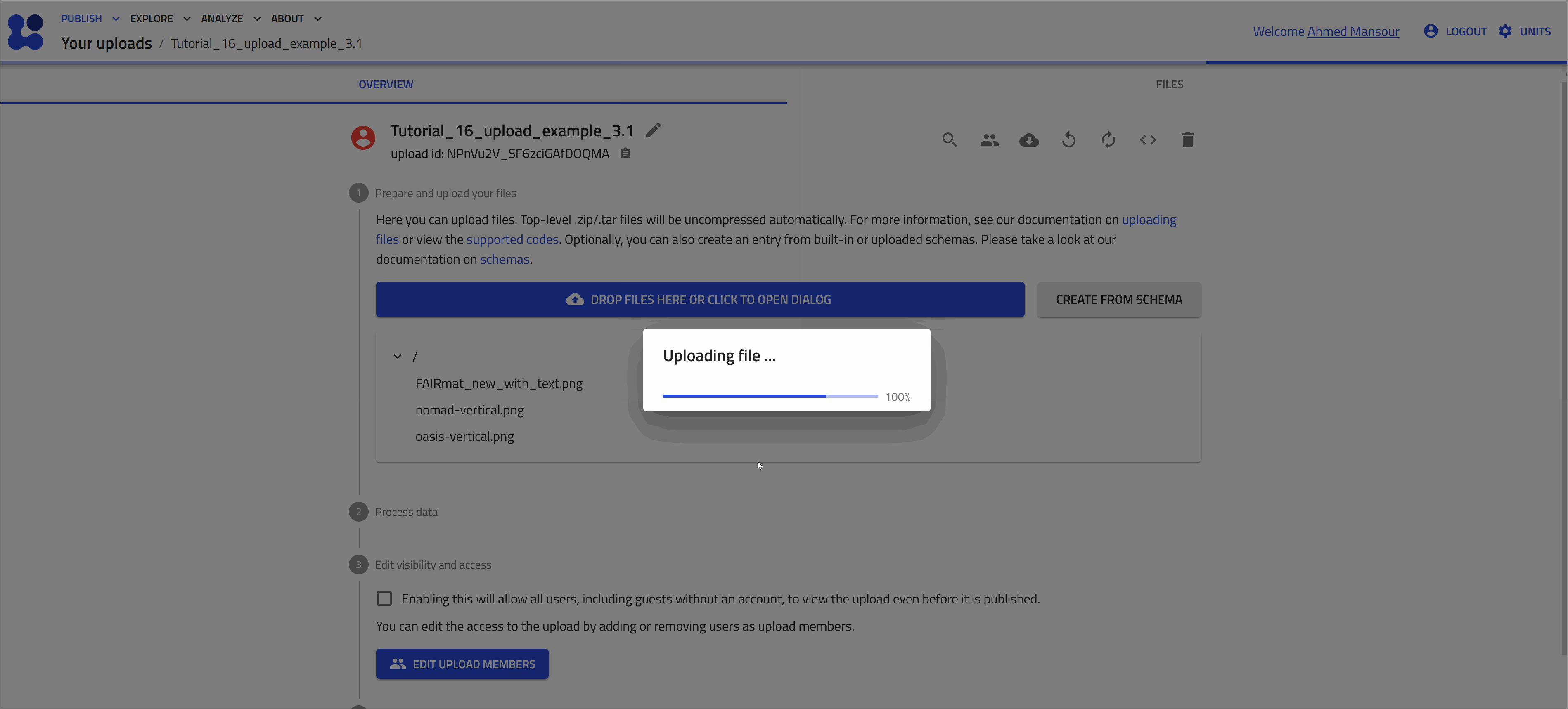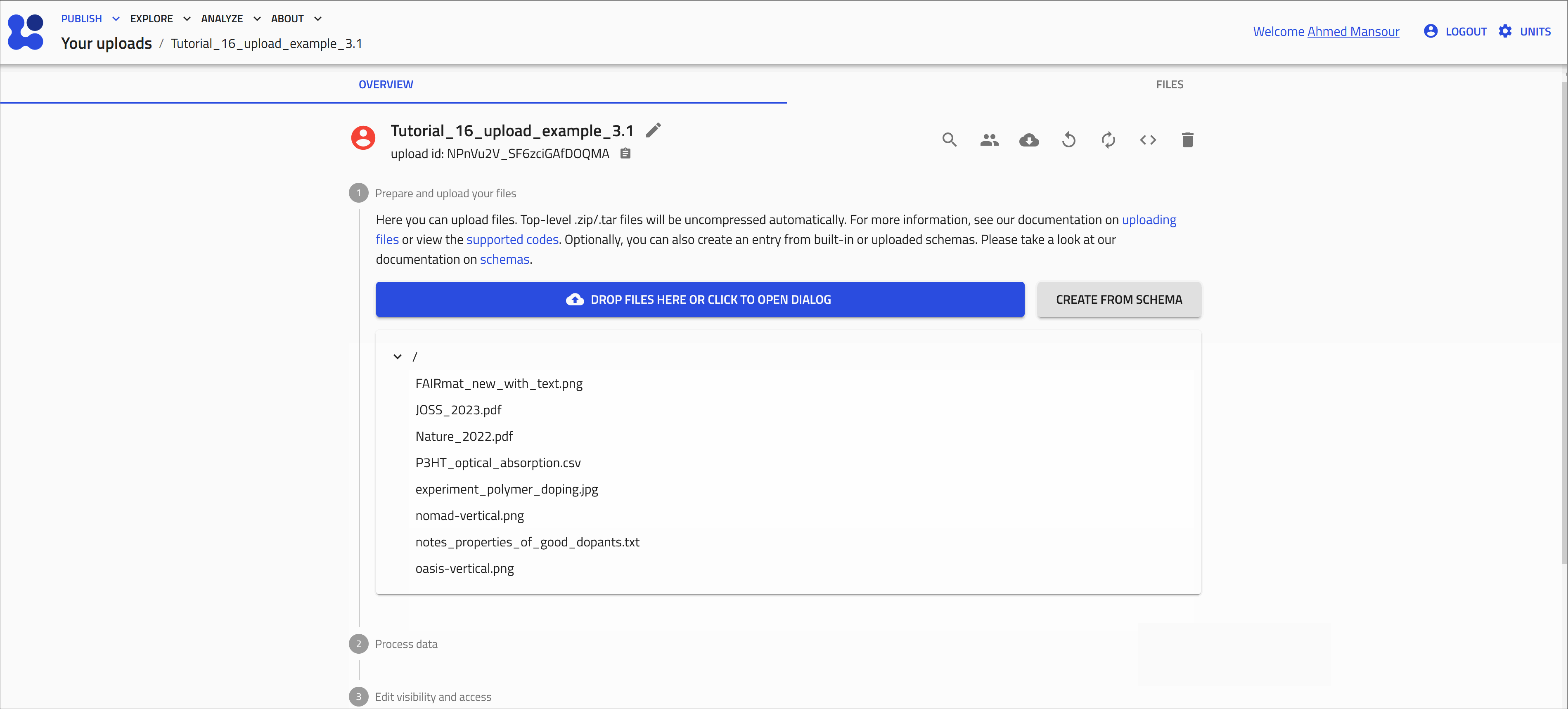
Upload computational data¶
Download the example files for this exercise
Download the folder to your local machine at you preferred directory.
This folder contains the input and output files of a DFT calculation for Iron(III) Oxide using the FHI-aims code.
FHI-aims is an all-electron density-functional-theory package that employs numeric atom-centered basis functions. It is designed for accurate and efficient simulations of molecules, clusters, surfaces, and bulk materials across the periodic table. Its advanced treatment of electronic structure allows for precise calculations of material properties, including band structures, total energies, and magnetic properties. More information in this link
The calculations in this example were performed using a code that is supported by NOMAD, i.e. the FHI-aims code.
NOMAD has a parser for the FHI-aims code. This means it will create an entry for these data.
In other words, NOMAD will read the input and output files and provide all information in NOMAD's unified metainfo data schema.
Uploading input and output files .zip of a DFT calculation
Uploading the files
Start with uploading the file FHI-aims.zip. Let's use the drag and drop method as shown in the animation below.
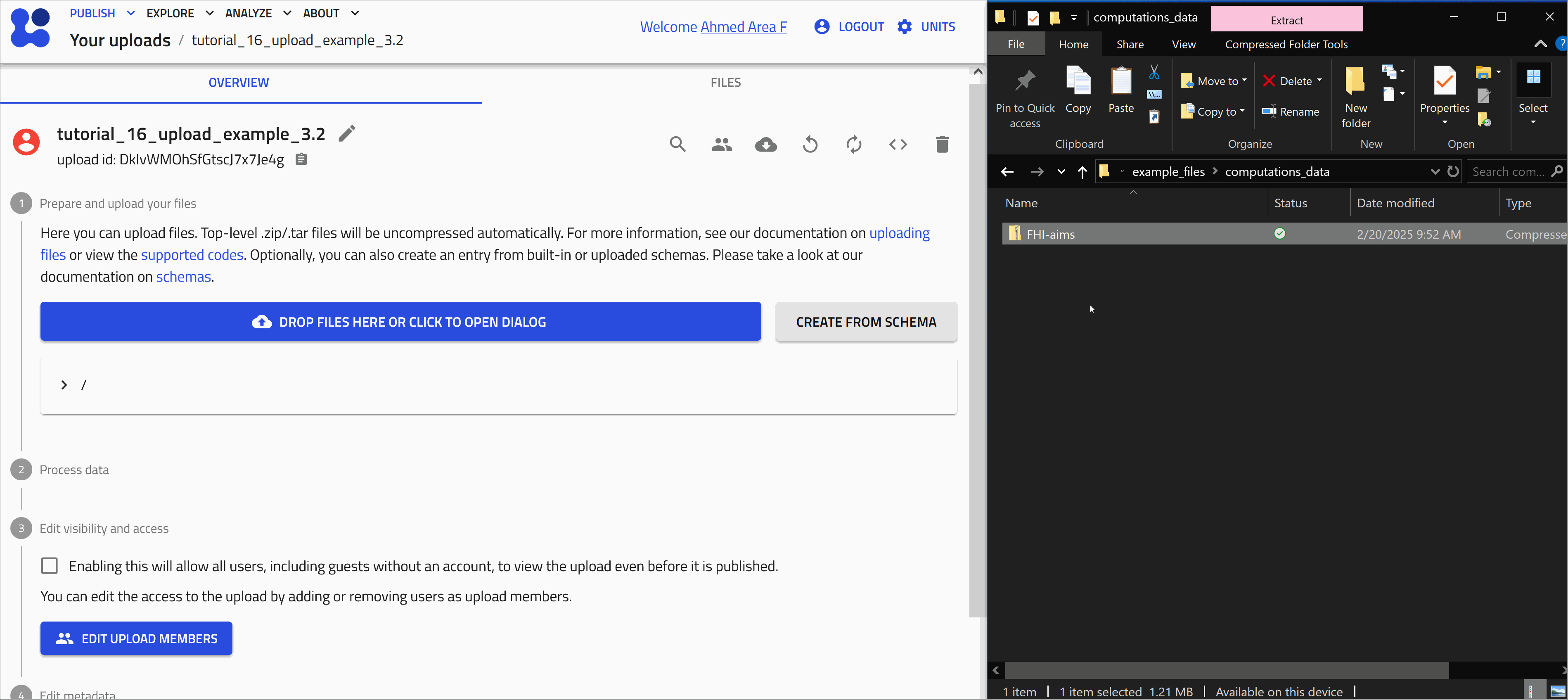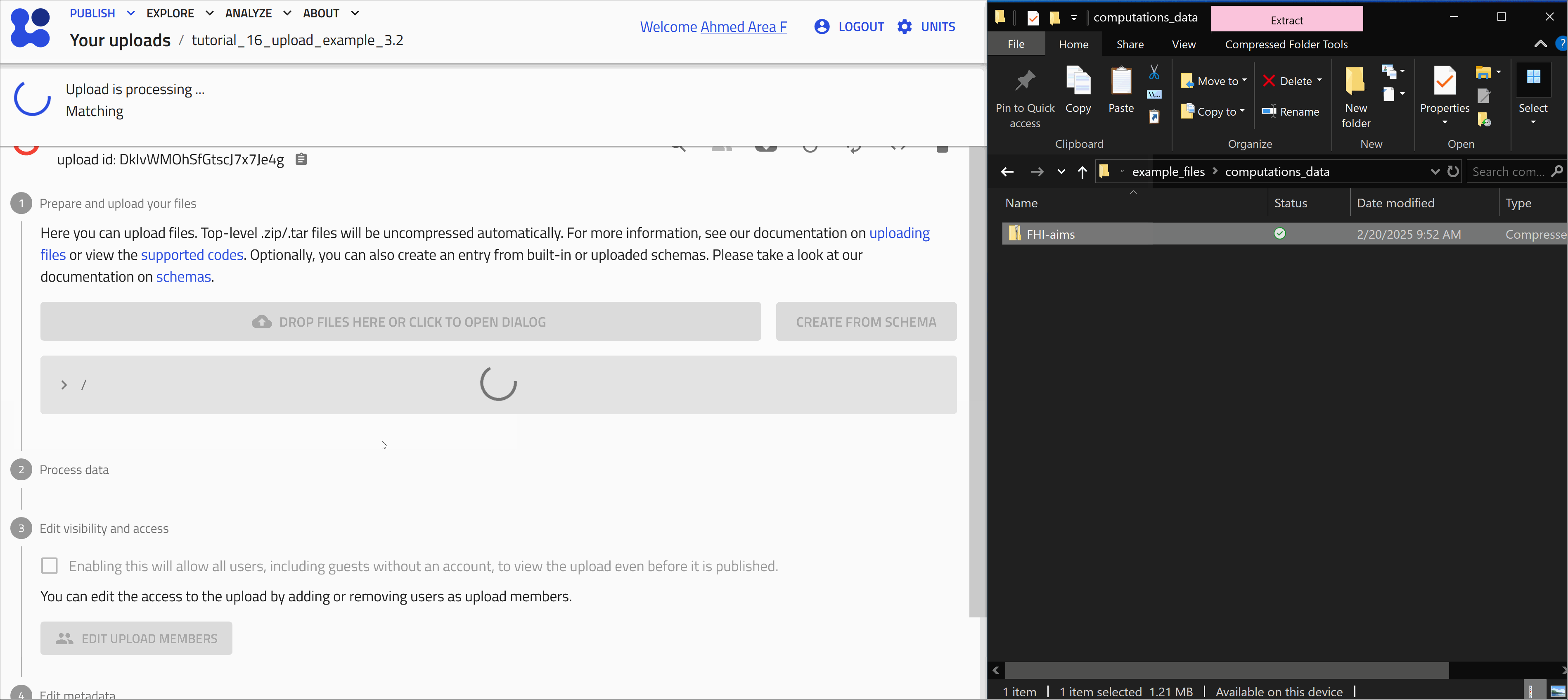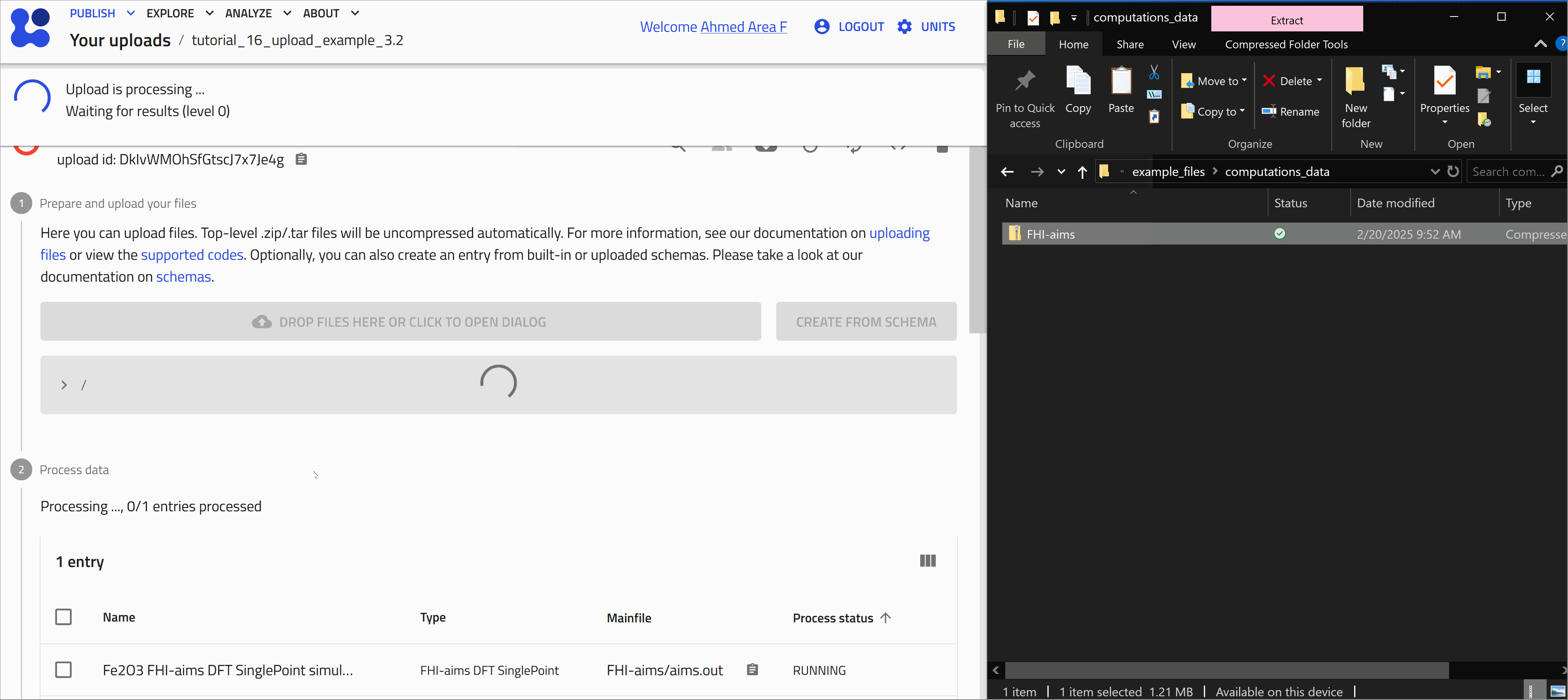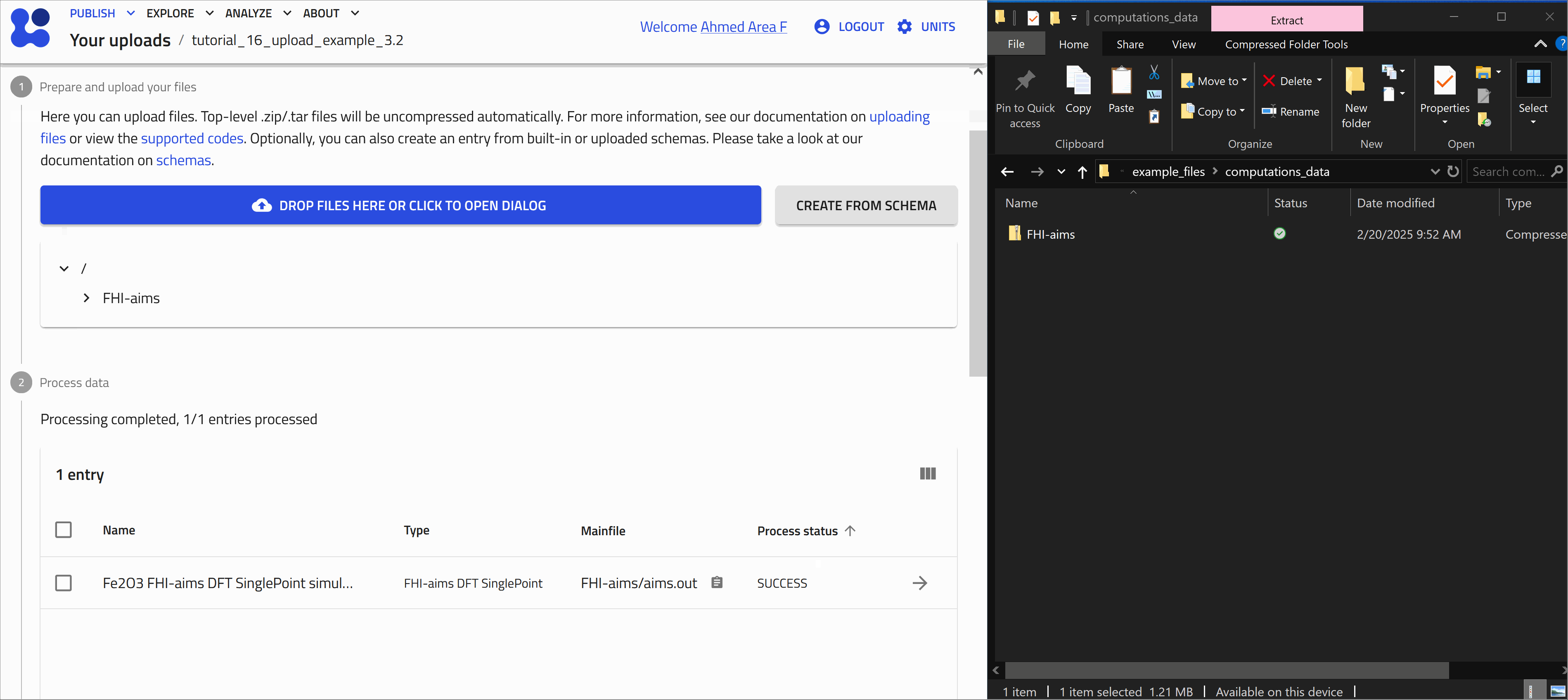
After uploading files, processing is automatically triggered. This involves identifying supported file formats in NOMAD and extracting relevant (meta)data. The exact processing steps depend on the use case. For example, you can learn more about the processing of computational data on this link.
Once processing is complete, NOMAD generates an entry page that presents the data in a structured, hierarchical format based on the NOMAD metainfo schema.
Opening and exploring your entry
To go to the entry page, click on the ![]() icon next to the entry. Here you can view the metadata and useful visualization of your data, check the uploaded files, and explore your entry in detail.
icon next to the entry. Here you can view the metadata and useful visualization of your data, check the uploaded files, and explore your entry in detail.
-
OVERVIEW tab:
1- On the left, core metadata are displayed.
2- On the right, various cards present the available information.
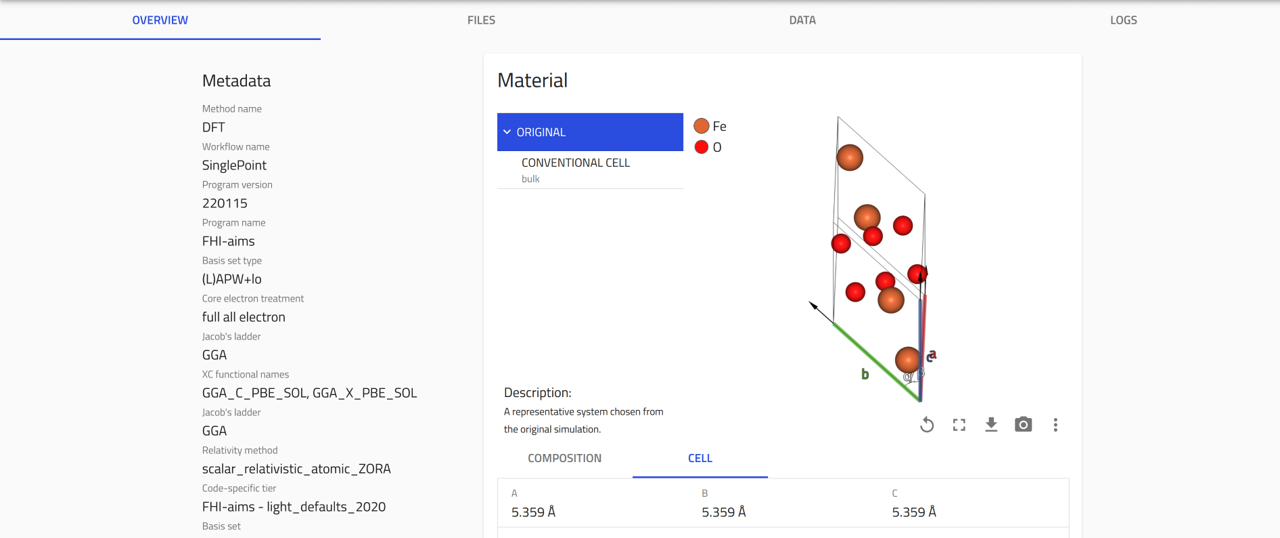
The cards you see depend on the properties or data available for that entry.
For FHI-aims files, three main cards appear in the overview page:
-
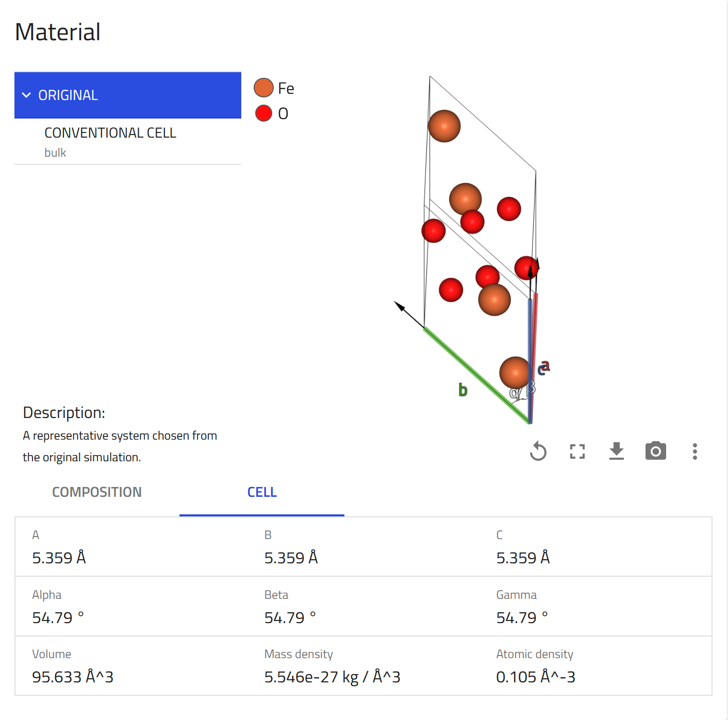
Materials card: Shows key information and visualization of the composition and conventional cell.
-
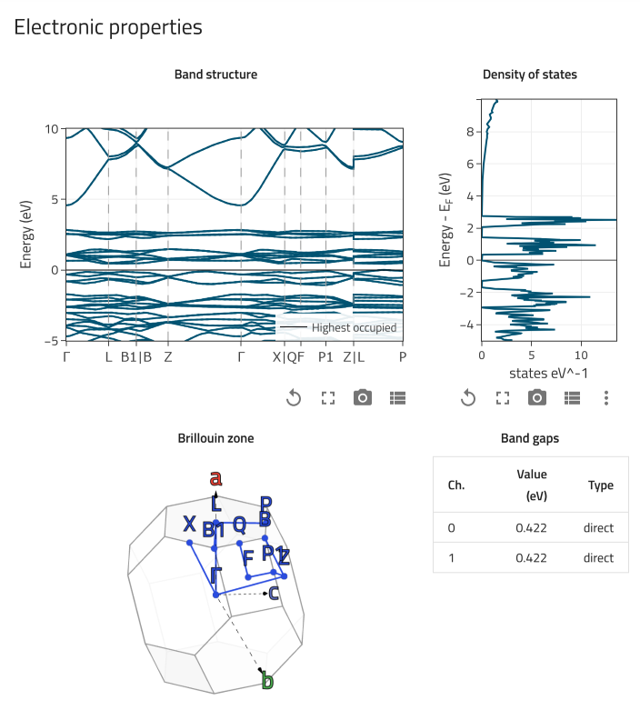
Electronic properties card: Shows the calculated band structure, density of states, and Brillouin zone.
-
Workflow Graph card: Illustrates the various steps in the calculation, including their inputs and outputs.
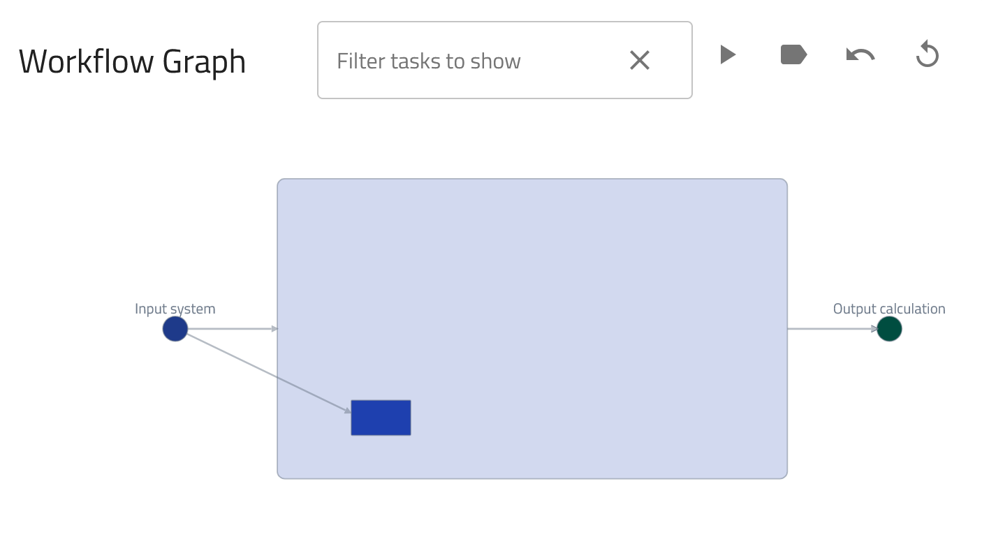
-
-
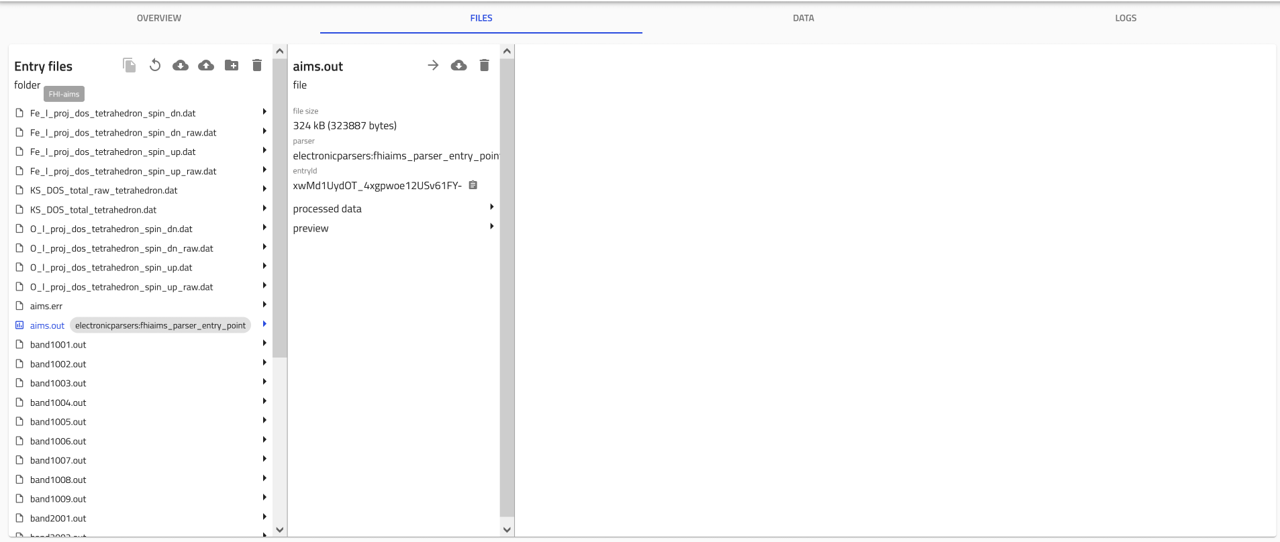
FILES tab:
This tab shows the uploaded files. NOMAD lists all files in the same directory, as they usually belong together.
-
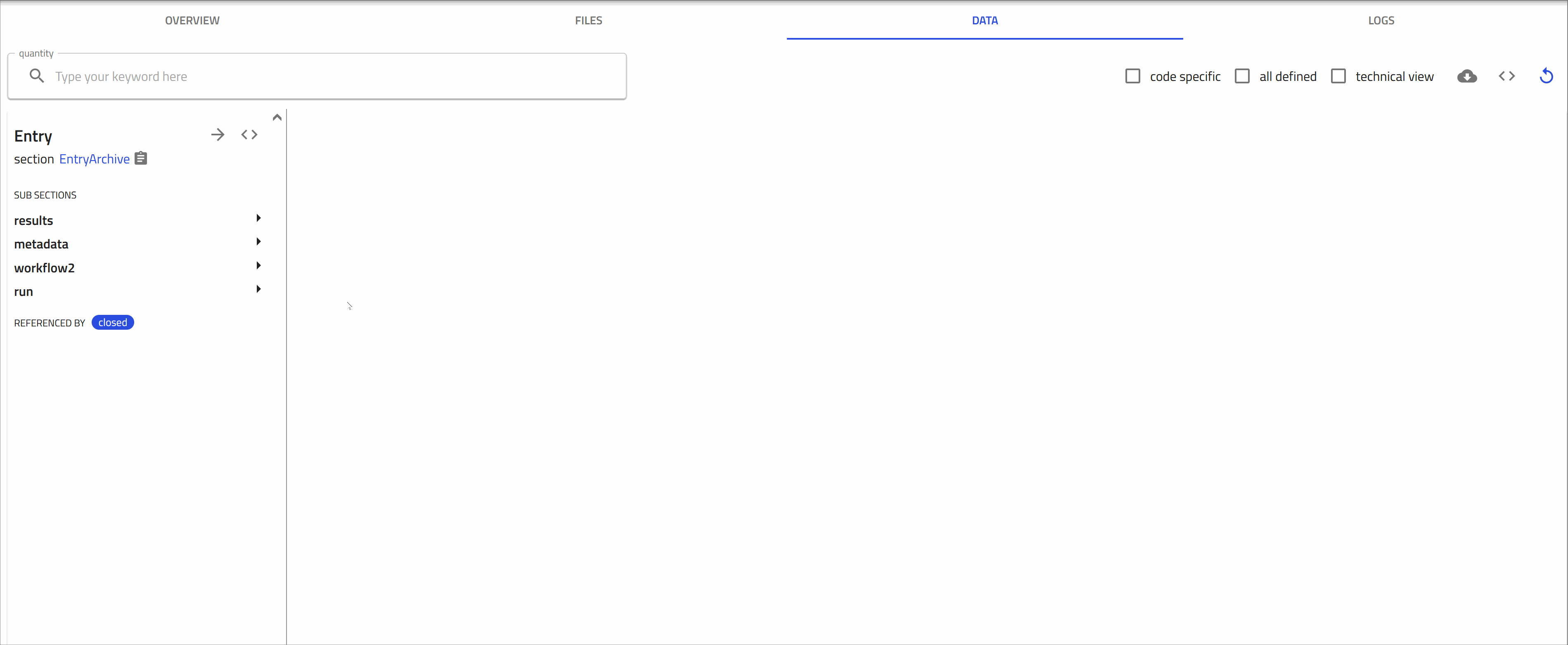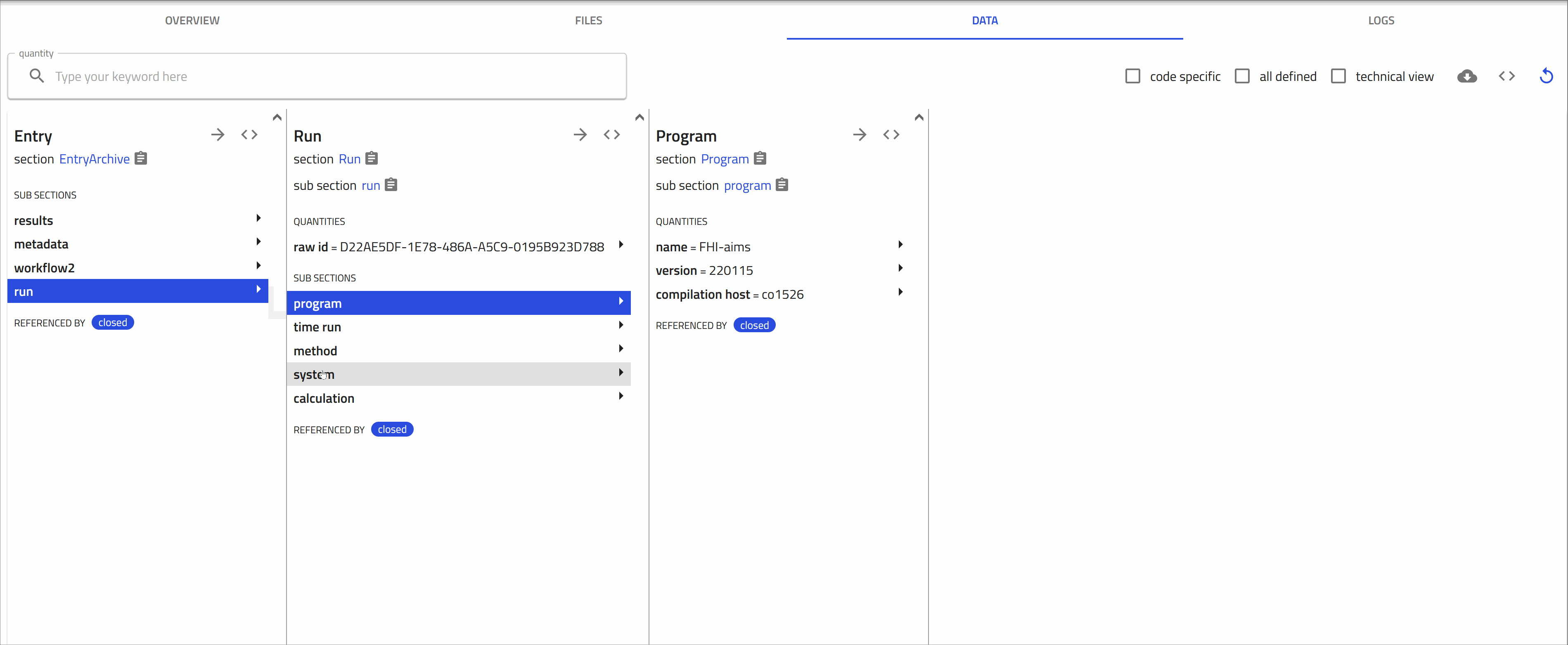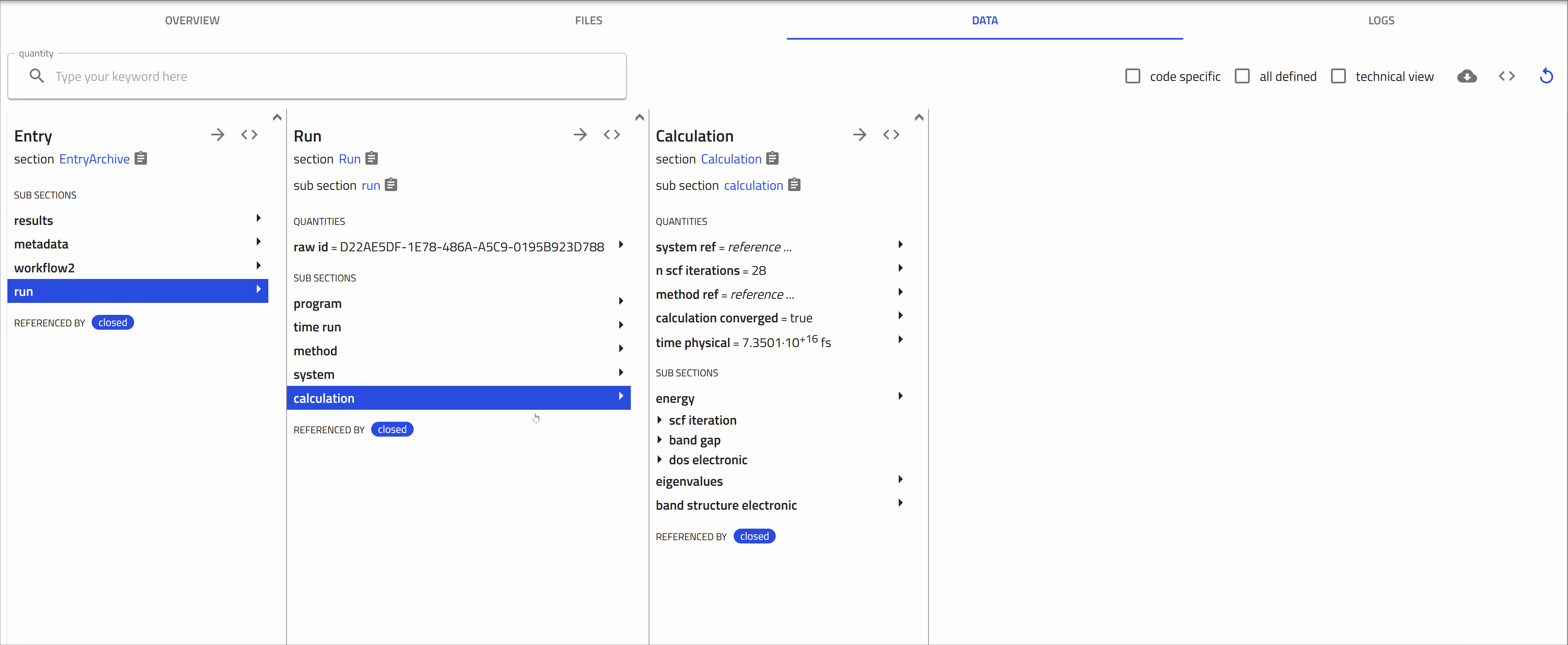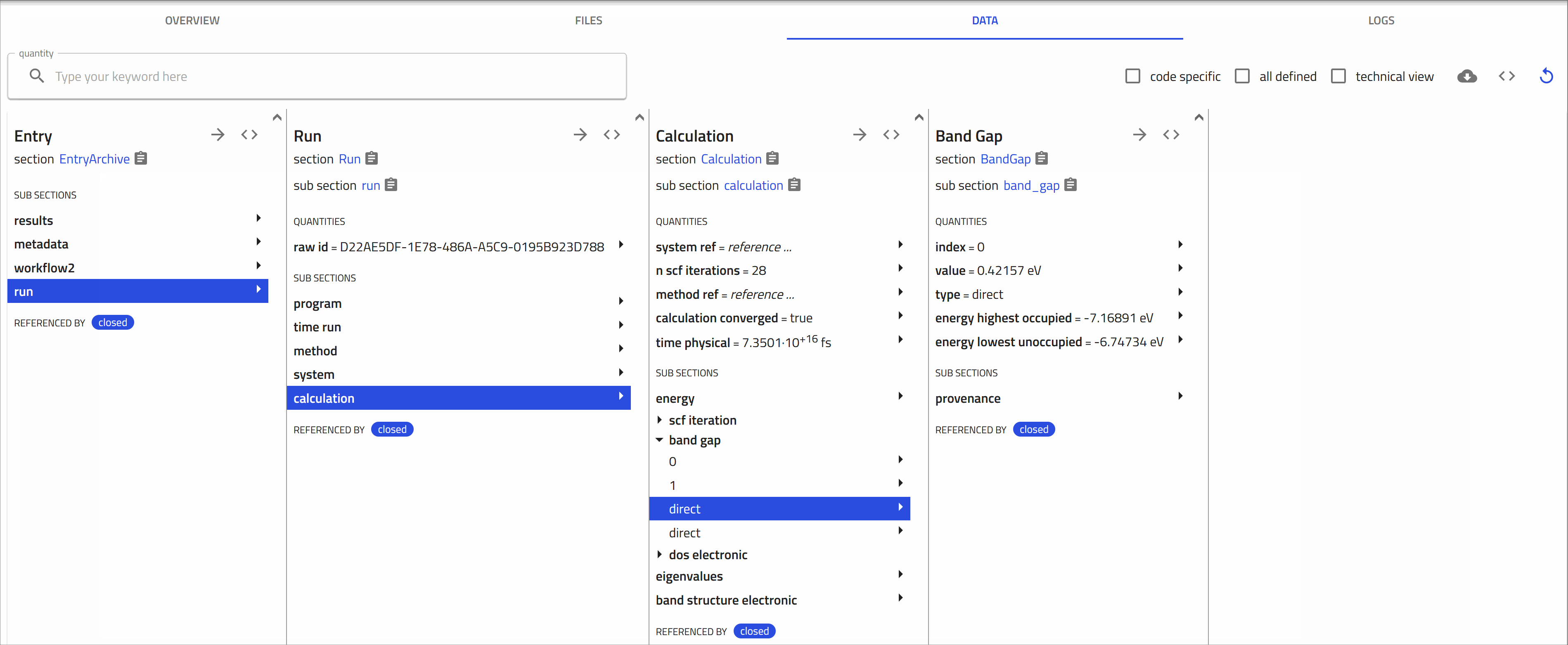
DATA tab:
Also known as the "processed data" tab, this shows the results of the parsing and normalization process done by NOMAD.
NOMAD puts all the data in a unified, hierarchical, and machine-processable format, following the NOMAD metainfo.
Upload experimental data¶
Download the example files for this exercise
Download the folder, then uncompress it to your local machine at you preferred directory.
This folder contains files related to an x-ray photoelectron spectroscopy (XPS) on the polymer PBTTT using SPECS spectrometer.
It includes the data in two formats (.nxs and .xml), in addition to an electronic lab notebook (ELN) file (.yaml) documenting additional details of the experiment.
| file name | format | description |
|---|---|---|
| PBTTT_XPS_SPECS | .nxs | XPS data file in the standard NeXuS file format |
| PBTTT_XPS_SPECS_raw | .xml | XPS data in a raw file format as produced by the spectrometer |
| eln_data_xml | .yaml | An ELN file used to record additional metadata of the experiment |
NOMAD supports experimental data files in the .nxs format.
These files can be uploaded directly to NOMAD, where they are processed, and structured Entries are created.
Uploading experimental data in the .nxs format
Uploading the file
Start with uploading the file PBTTT_XPS_SPECS.nxs. Let's use the drag and drop method as shown in the animation below.
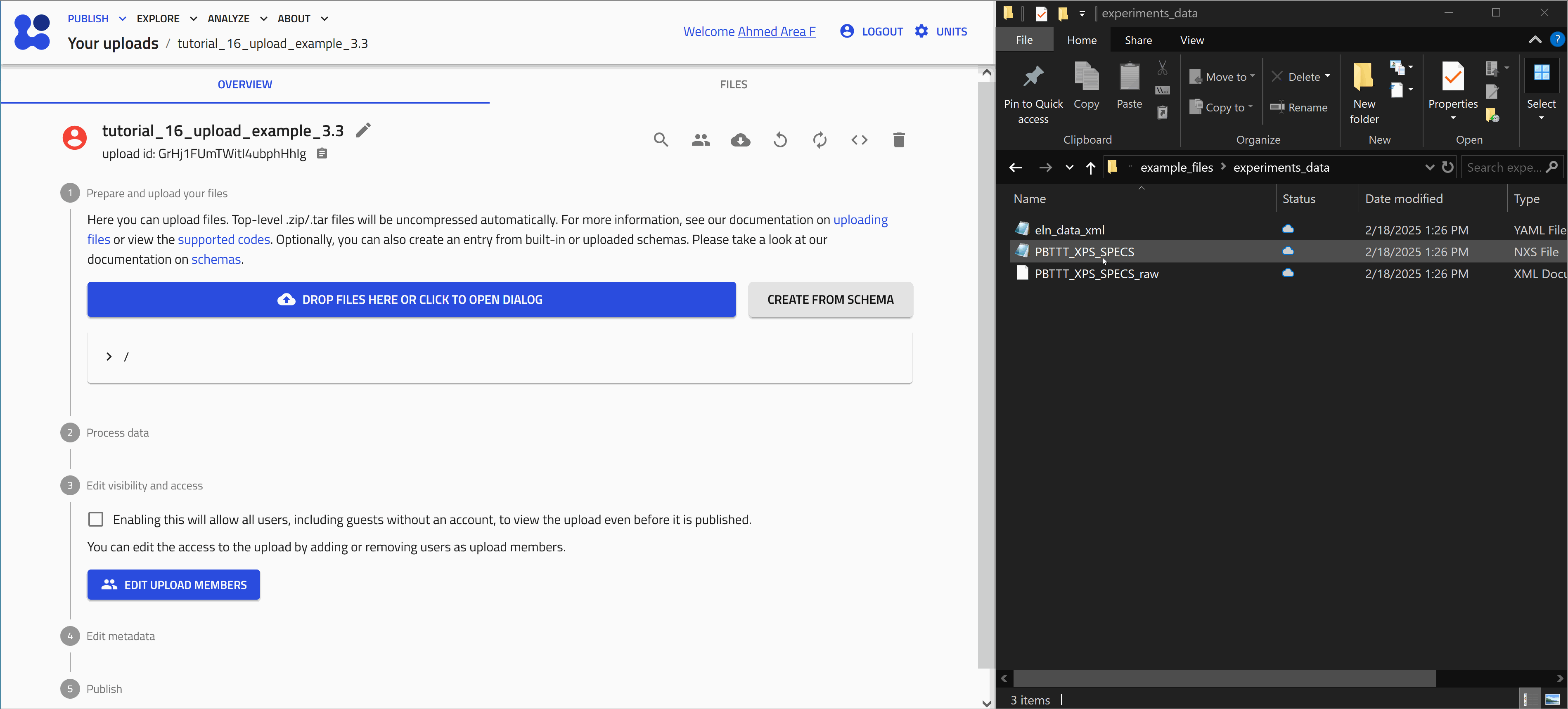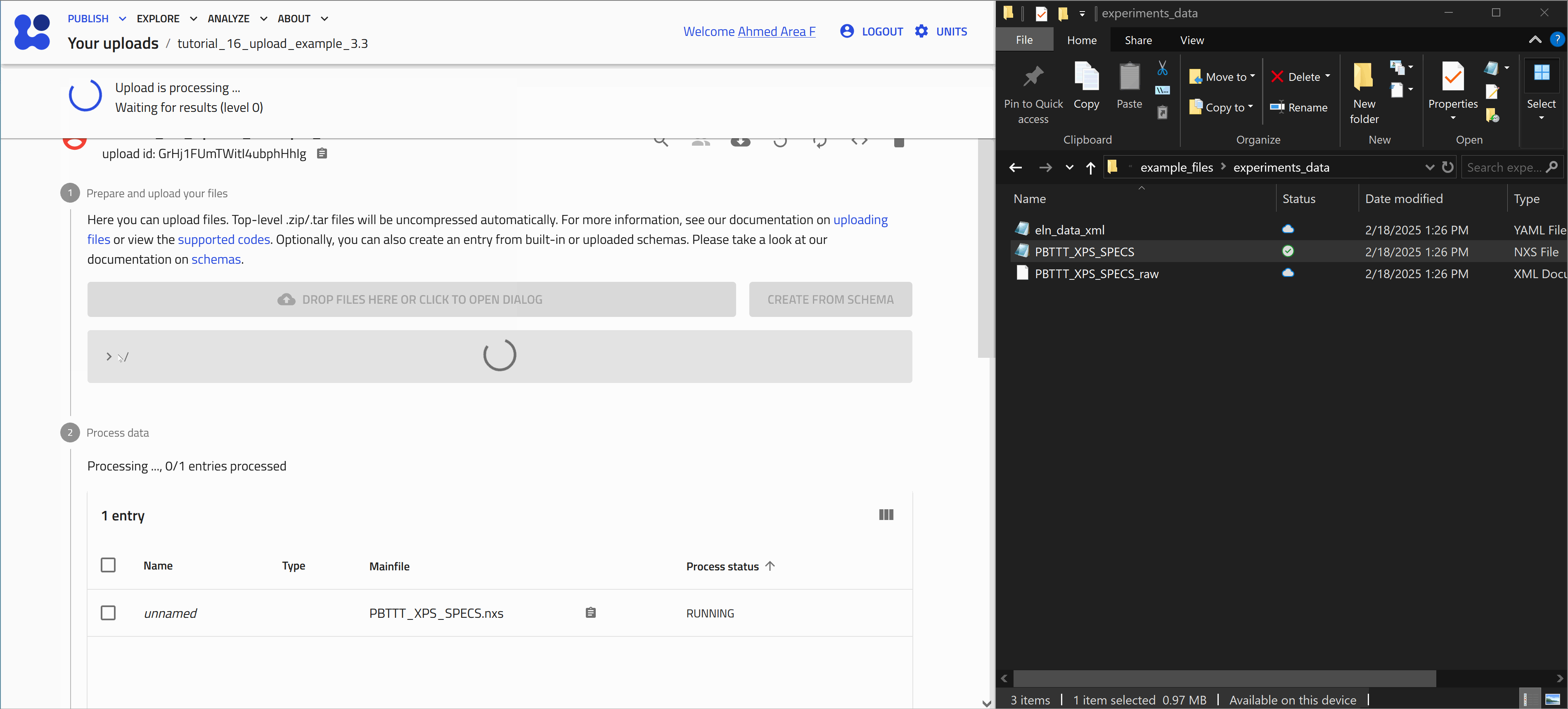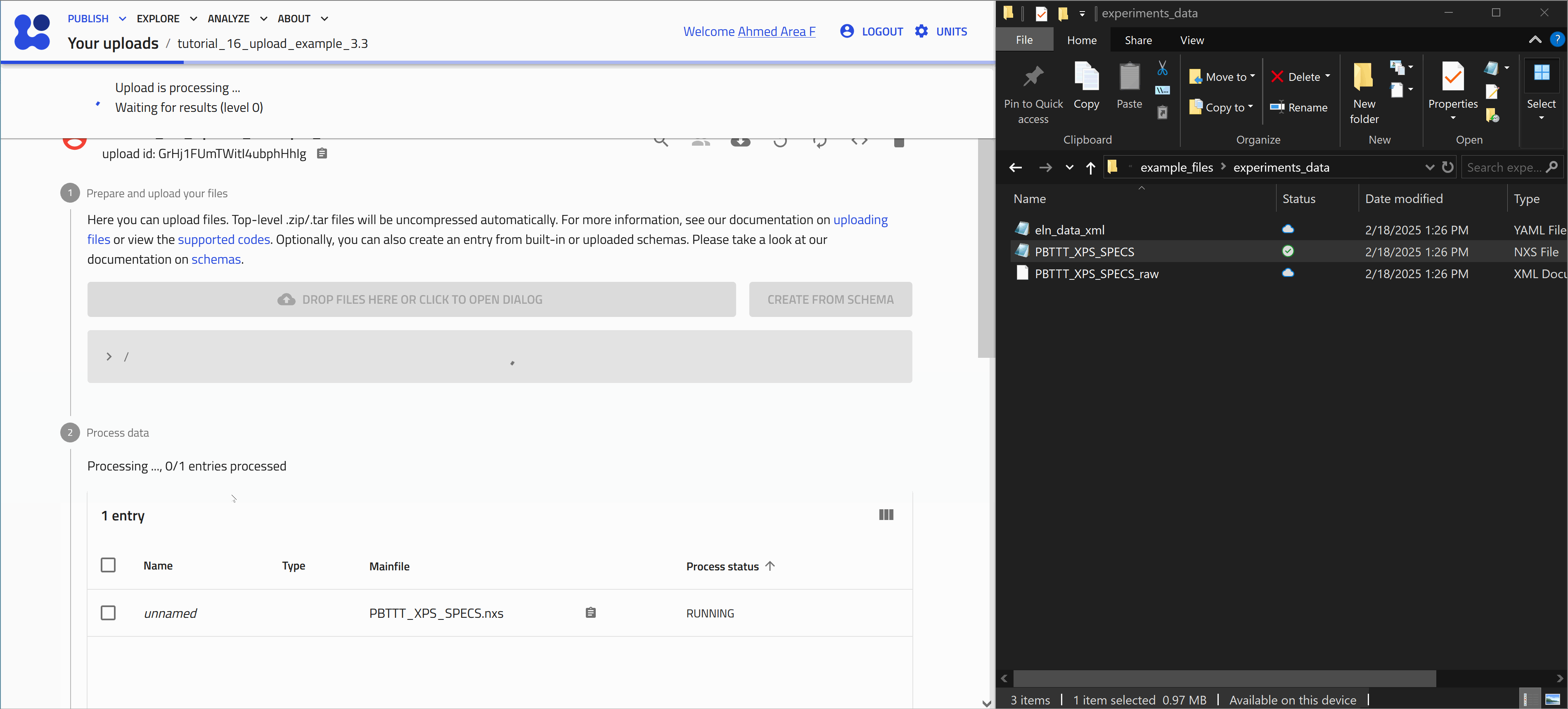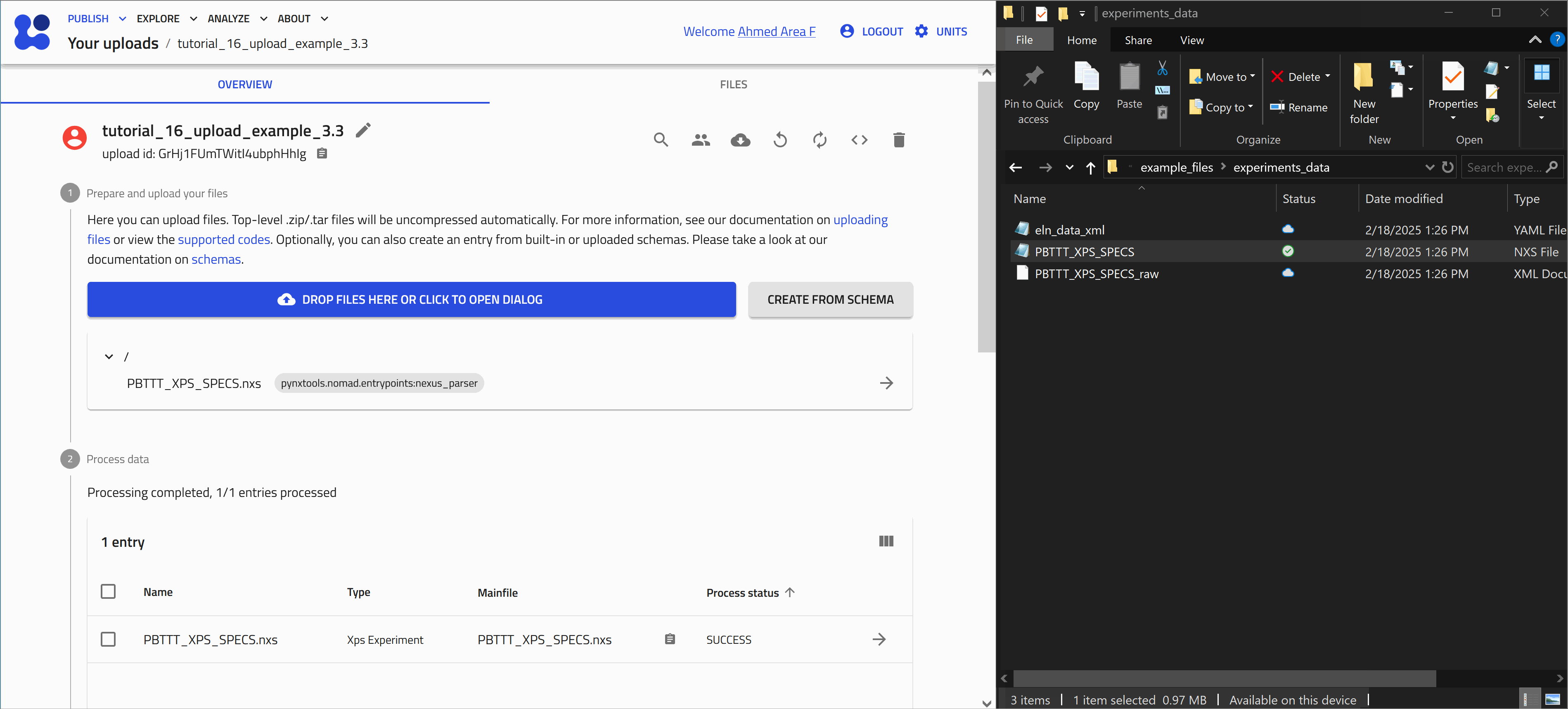
After uploading files, processing is automatically triggered. This involves identifying supported file formats in NOMAD and extracting relevant (meta)data. The exact processing steps depend on the use case.
Once processing is complete, NOMAD generates an entry page that presents the data in a structured, hierarchical format based on the NOMAD metainfo schema.
Opening and exploring the entry
Click on the ![]() icon next to an entry navigates you to the respective entry page.
icon next to an entry navigates you to the respective entry page.
Here you can view the metadata and useful visualization of your data, check the uploaded files, and explore your entry in detail.
-
OVERVIEW Tab:
1- On the left, core metadata are displayed.
2- On the right, various cards present the available information.
The cards you see depend on the properties or data available for that entry.
For
.nxsfiles, two main cards appear in the overview page: the data viewer and the materials card.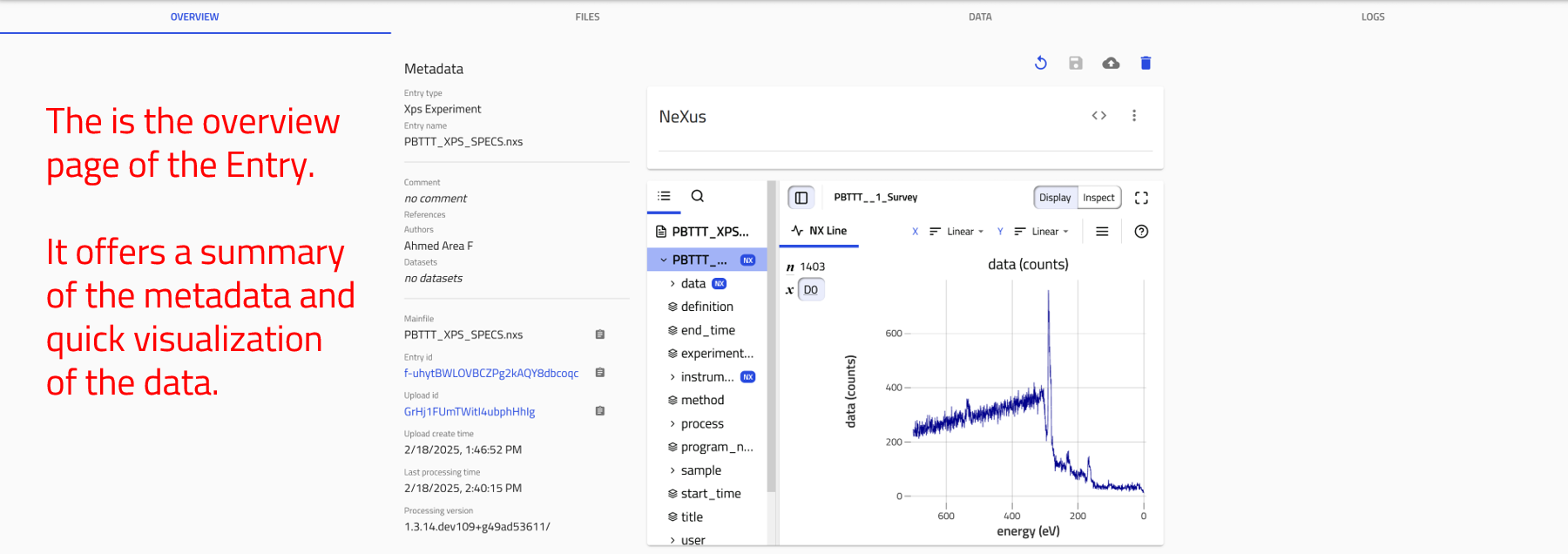
-
FILES Tab:
This tab shows the uploaded files. NOMAD lists all files in the same directory, as they usually belong together.
-
DATA Tab:
Also known as the "processed data" tab, this shows the results of the parsing and normalization process done by NOMAD.
NOMAD puts all the data in a unified, hierarchical, and machine-processable format, following the NOMAD metainfo.

Most scientific instruments generate experimental results in formats other than .nxs. NOMAD still supports these files by providing a conversion process using the NexusDataConverter built-in schema, which transforms raw data into the .nxs format.
NexusDataConverter readers and the NeXuS application definitions
A Reader is a program designed to interpret and extract data from a specific experimental technique or file format.
The reader understands the structure and encoding of the particular data format and provides methods for accessing its contents in a programmatically friendly way. It acts as a bridge between raw experimental data and NOMAD by converting the data into the structured file format according to domain-specific application definitions.
A list of available readers can be found here
A NeXus application definition provides a structured specification of the terms and metadata required in an .nxs data file for a particular scientific application. These definitions outline the minimum set of terms that must be included in the data file for it to be considered valid according to the NeXus format.
A list of NeXuS application definitions developed by FAIRmat can be found here
NexusDataConverter uses readers to interpret the raw data files, and then structures them according to the outlines of the application definitions.
In the following examples, you will learn how to upload a raw file from a SPECS instrument in .xml format by using the NexusDataConverter. You will do this in two ways:
- Uploading only the raw file.
- Uploading both the raw file and an ELN file, enriching your data with metadata and ensuring compliance with community standards.
Uploading experimental data in the .xml format
Step 1: Click on the CREATE FROM SCHEMA button in your upload page.
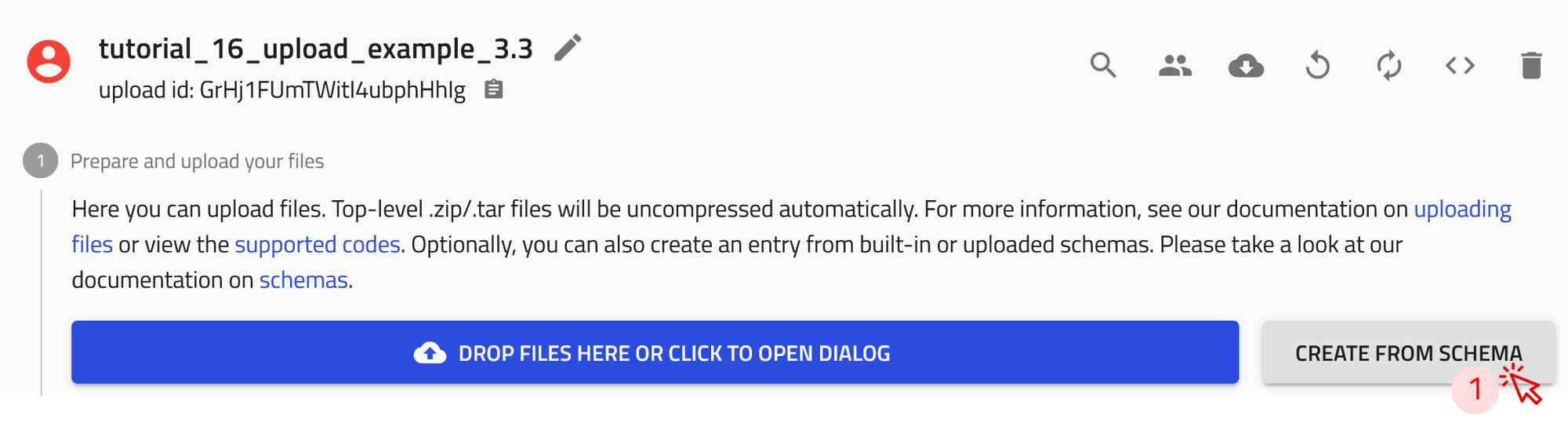
Step 2: In the create new entry from schema window, click on the drop-down menu of the built-in schema, and select NexusDataConverter
Step 3: Give a descriptive name for the entry.
Step 4: Click on CREATE. This will take you the NexusDataConverter entry page.
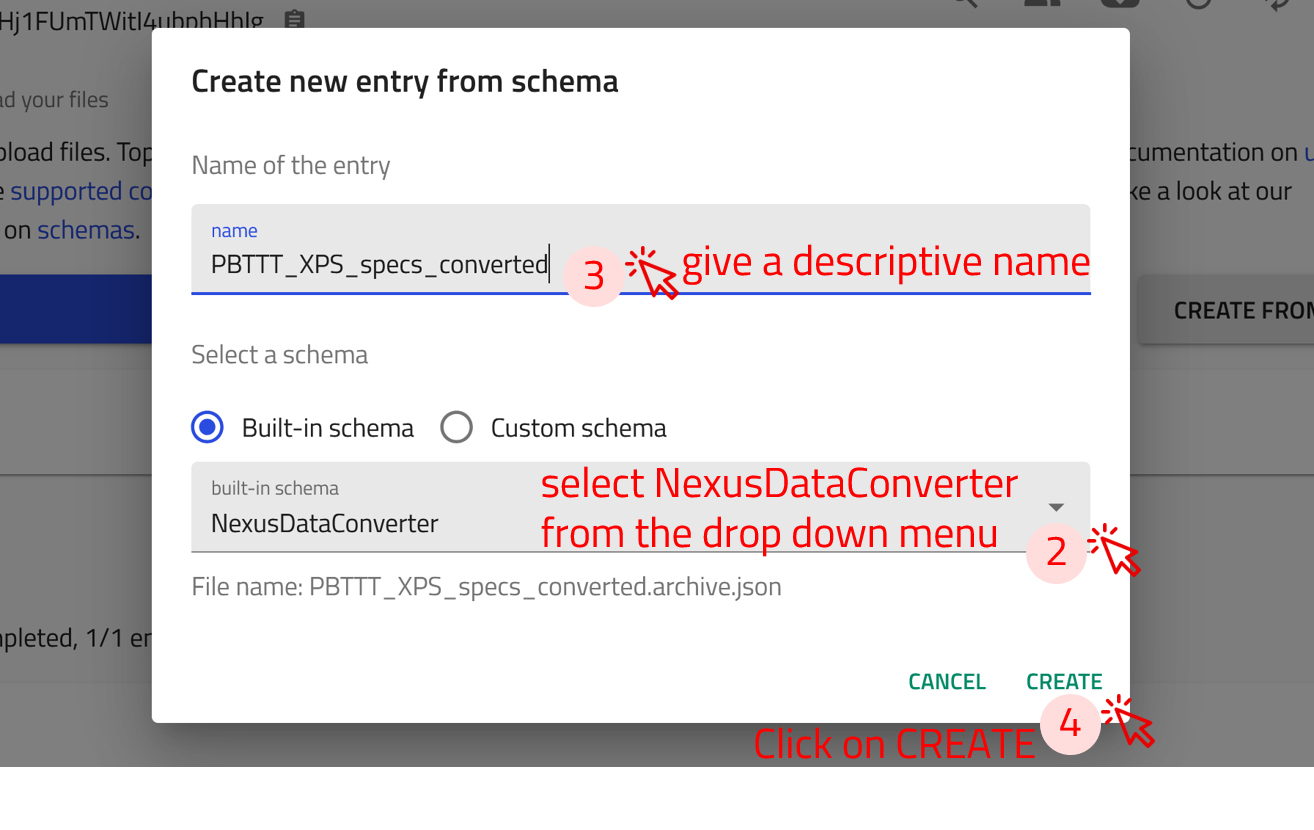
Step 5: From the reader drop-down menu, choose the appropriate reader for your files. For this exercise select xps.
Step 6: From the nxdl drop-down menu, choose the appropriate application definition for your experiment. For this exercise select NXxps
Step 7: Upload the raw data file PBTTT_XPS_SPECS_raw.xml.
Step 8: Give a descriptive name for the generated .nxs file.
Step 9: Click on the save icon to start the conversion process.
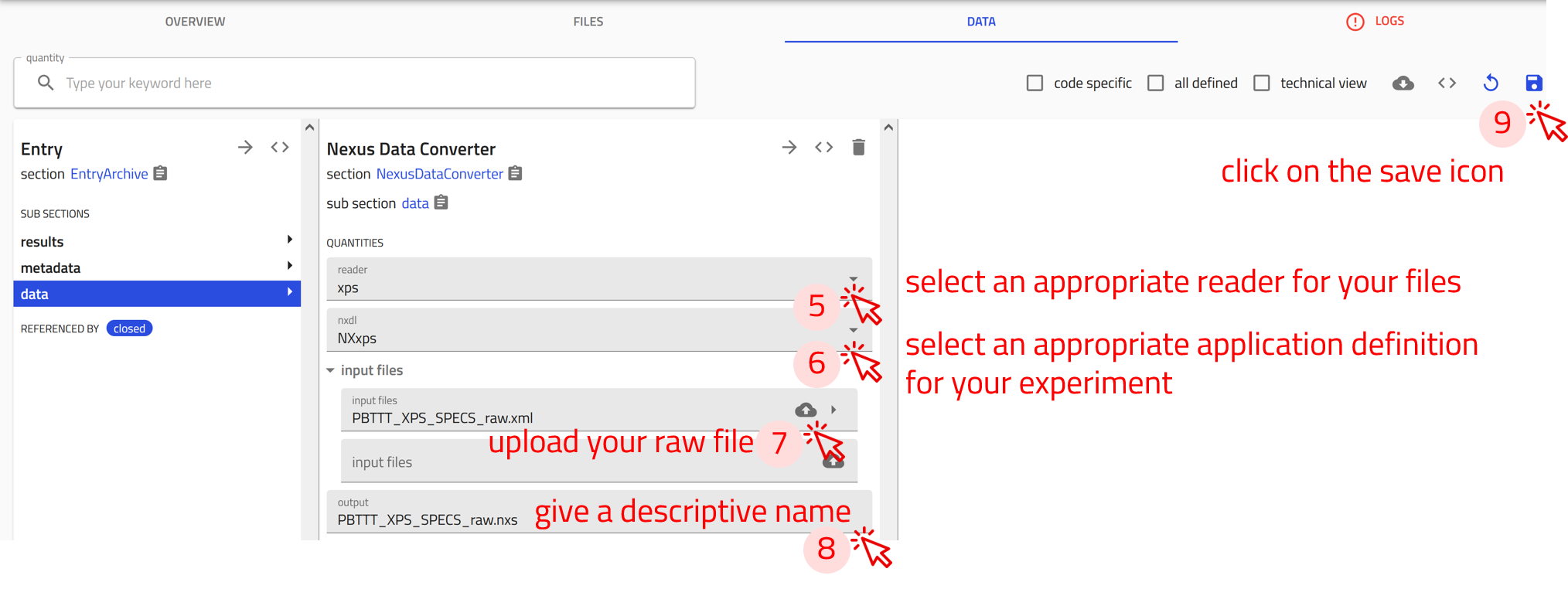
Check the overview page of your upload. There you will find two newly created entries; one for the NexusDataConverter and one for the generated .nxs file from your raw file.
NOMAD still stores your .xml raw file in the upload directory.
Uploading experimental data in the .xml format with additional ELN data
Often, raw files generated by instruments from various vendors lack complete metadata and essential details about the experiment.
To address this, scientists document all experimental details in an Electronic Lab Notebook (ELN). Combining data from raw files with information from ELNs ensures that experiments are comprehensively described with rich metadata and conform to community standards.
NOMAD’s NexusDataConverter allows you to merge experimental raw data files with ELN entries in .yaml format, producing .nxs files that meet community standards and ensure your data are richly-described.
The ELN .yaml file can be generated by various ELN software tools or created manually using a text editor.
For each supported experimental raw file format, FAIRmat provides a template ELN .yaml file containing all necessary attributes and parameters to complement the raw file’s data. These templates can be found here
While these files can be edited with any text editor, we recommend using VS Code for an optimized editing experience.
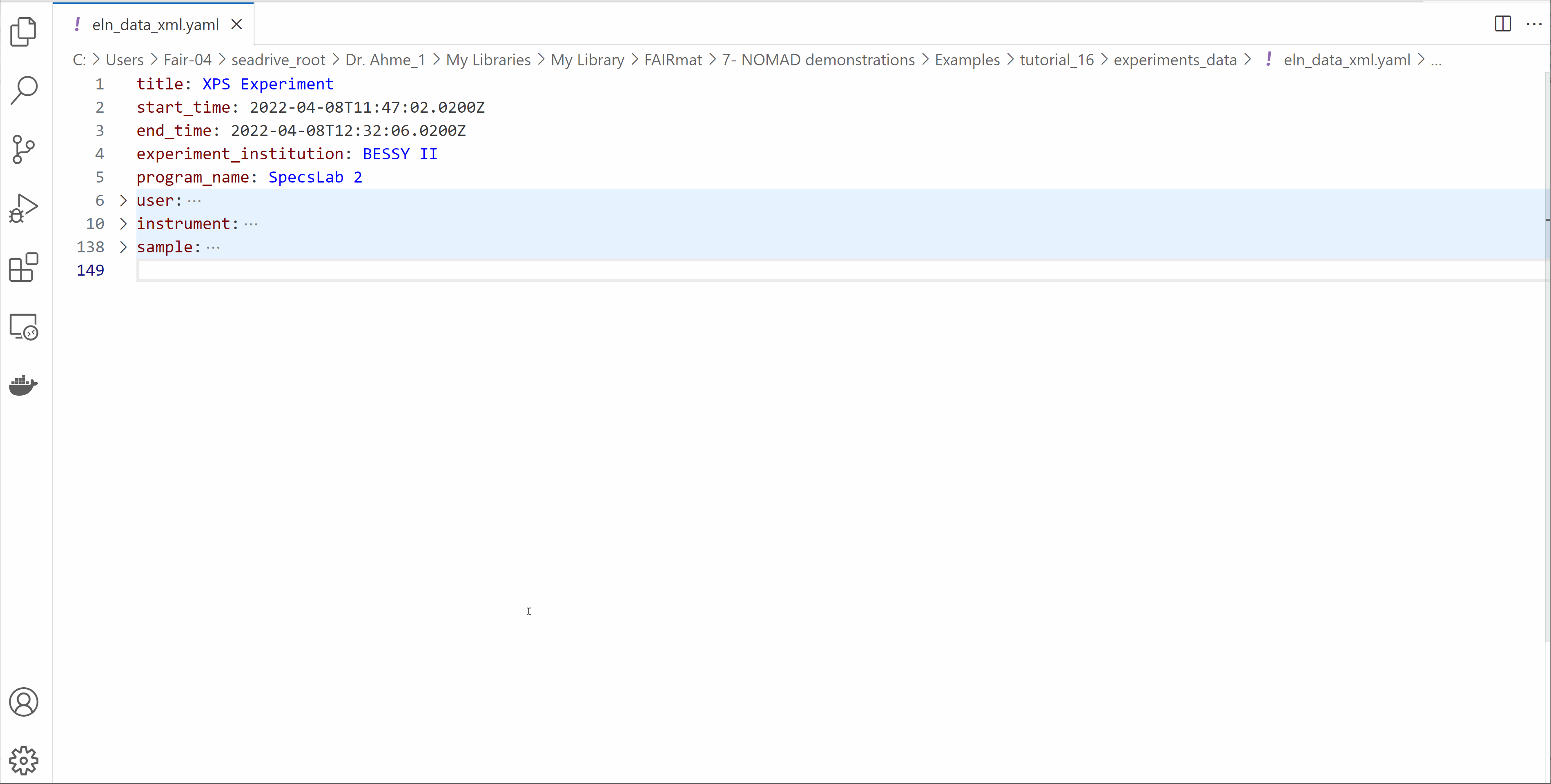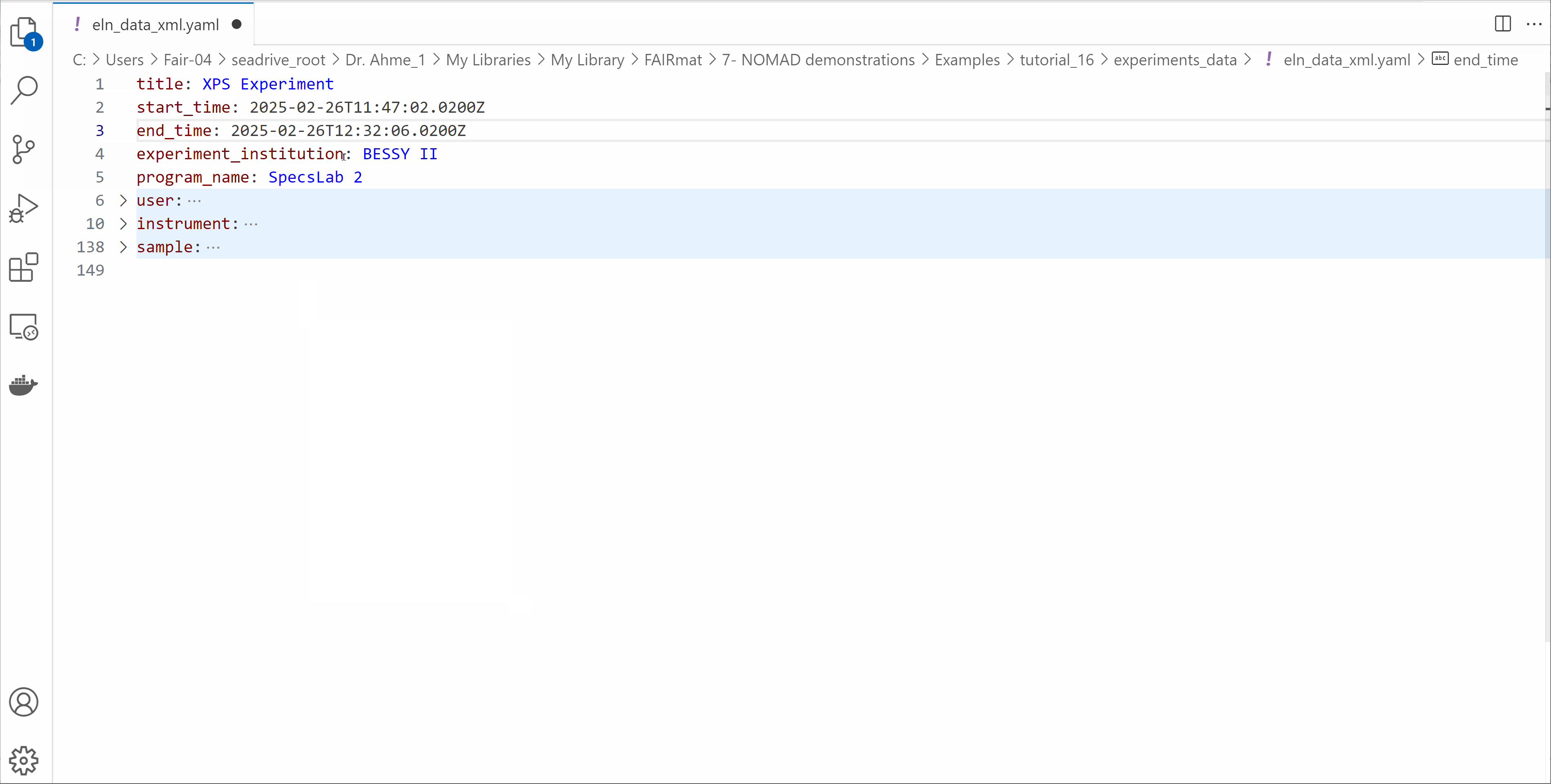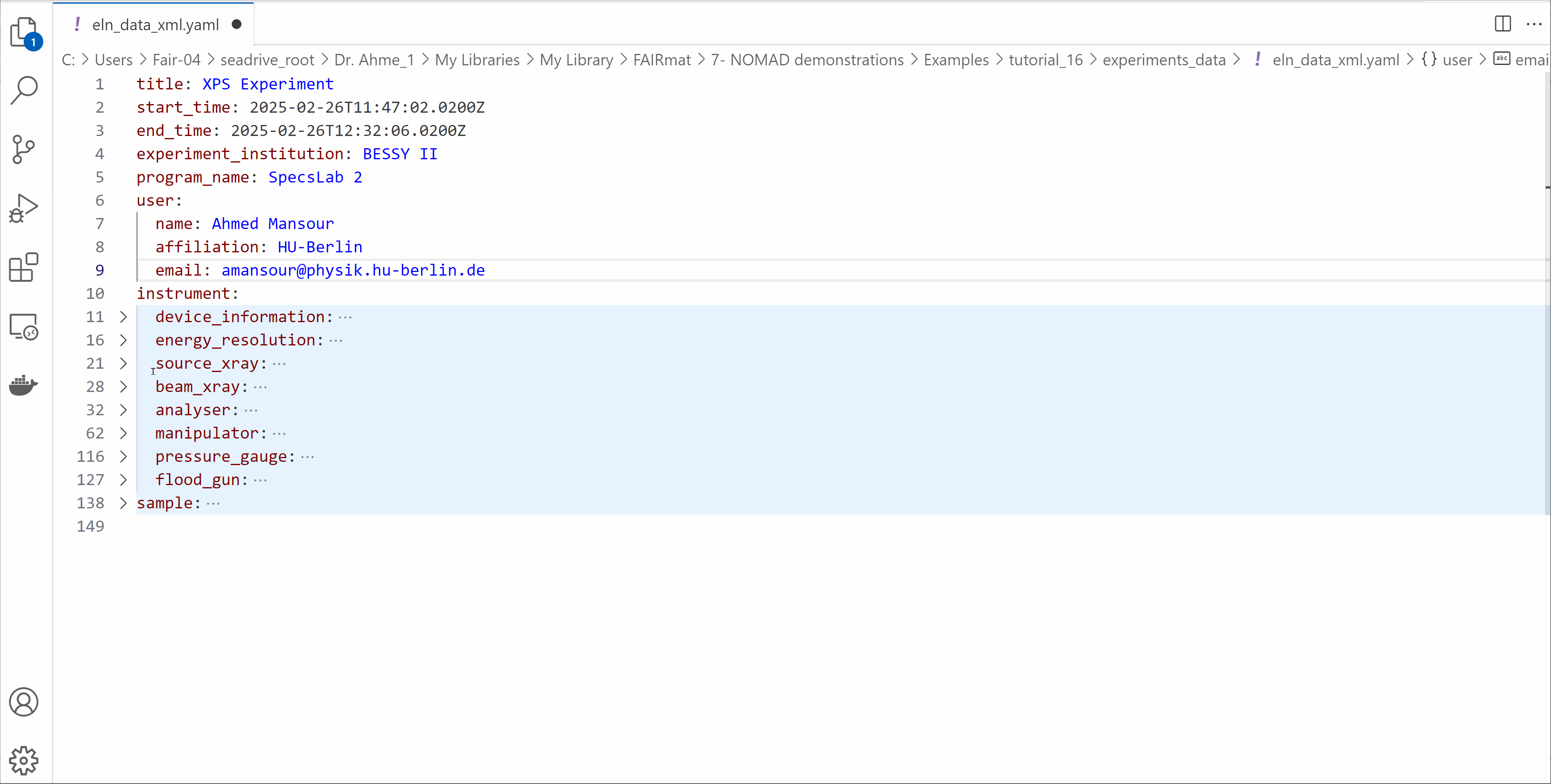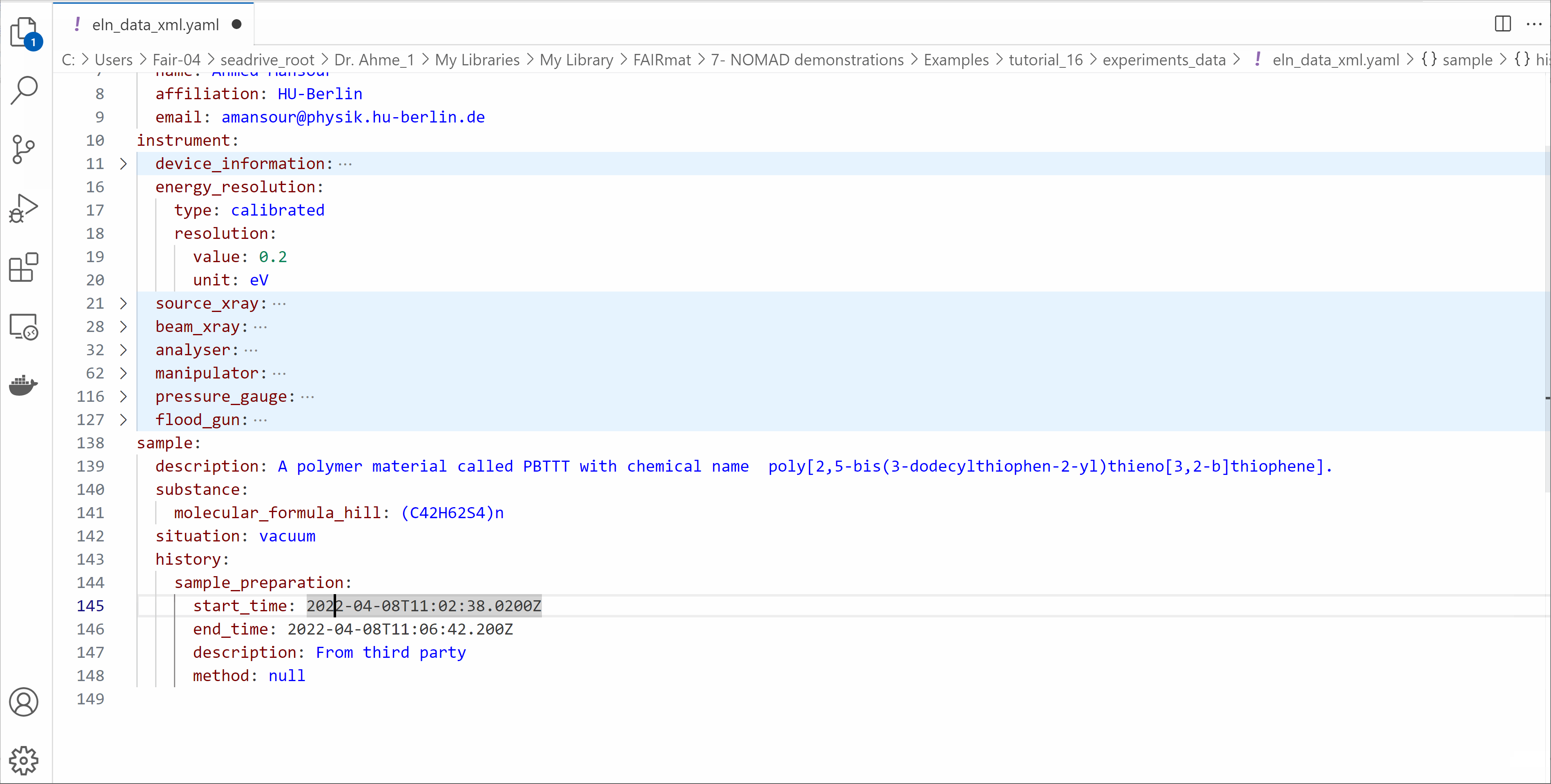
Open the eln_data_xml.yaml file and edit its contents
- Modify the start_time and end_time of your experiment.
- Write your information in the
userssection. - Explore the other fields available in the ELN file.
- Save the file.
Upload your data file .xml and your ELN data .yaml using NexusDataConverter
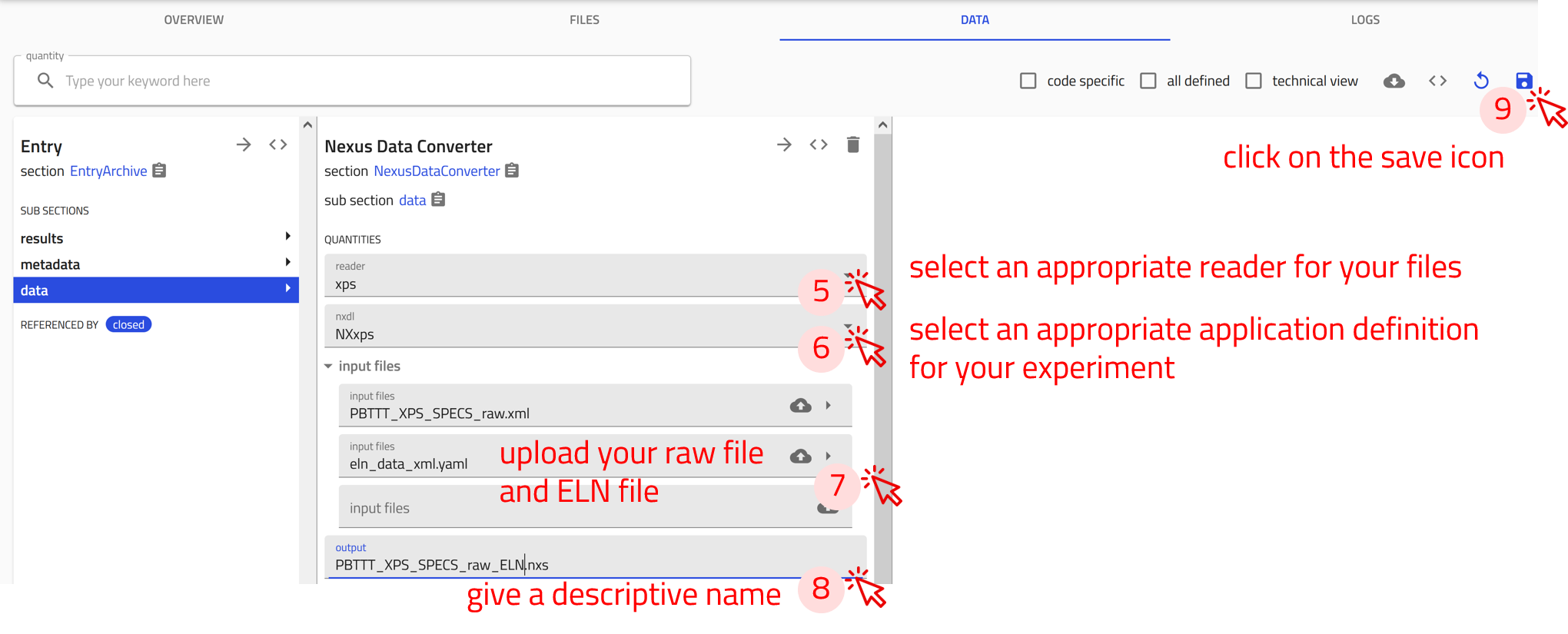
- Step 1: Click on the CREATE FROM SCHEMA button in your upload page.
-
Step 2: In the create new entry from schema window, click on the drop-down menu of the built-in schema, and select NexusDataConverter
-
Step 3: Give a descriptive name for the entry.
-
Step 4: Click on CREATE. This will take you the NexusDataConverter entry page.
-
Step 5: From the reader drop-down menu, choose the appropriate reader for your files. For this exercise select xps.
-
Step 6: From the nxdl drop-down menu, choose the appropriate application definition for your experiment. For this exercise select NXxps
-
Step 7: Upload the raw data file
PBTTT_XPS_SPECS_raw.xmlas well as the ELN data fileeln_data_xml.yaml. -
Step 8: Give a descriptive name for the generated
.nxsfile. -
Step 9: Click on the save icon to start the conversion process.
Create datasets and get a DOI¶
You can organize several entries by grouping them into common datasets, making it easier to manage related data. Datasets are for organizing and referencing curated data. They do not affect how data is processed. Users can get a DOI for their datasets.
Group entries into a dataset¶
Step 1: In the uploads page, click on EDIT AUTHOR METADATA OF ALL ENTRIES button. This will add all the Entries in the upload to the dataset.

Alternatively, if you would like to add selected entries from your Upload, click on the check box next to the entries you would like to add, then click on ![]() to open the EDIT AUTHOR METADATA window for the selected entries only.
to open the EDIT AUTHOR METADATA window for the selected entries only.
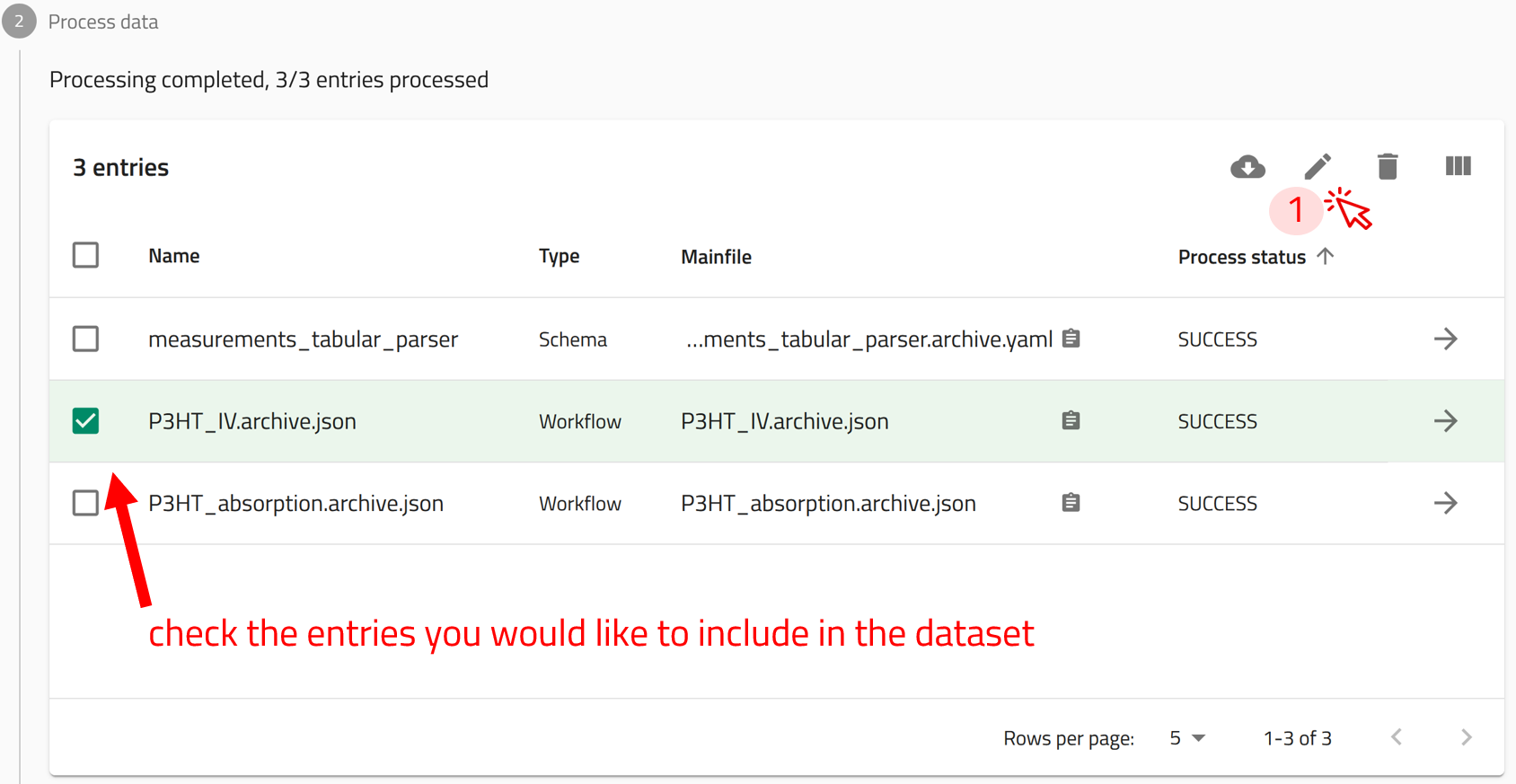
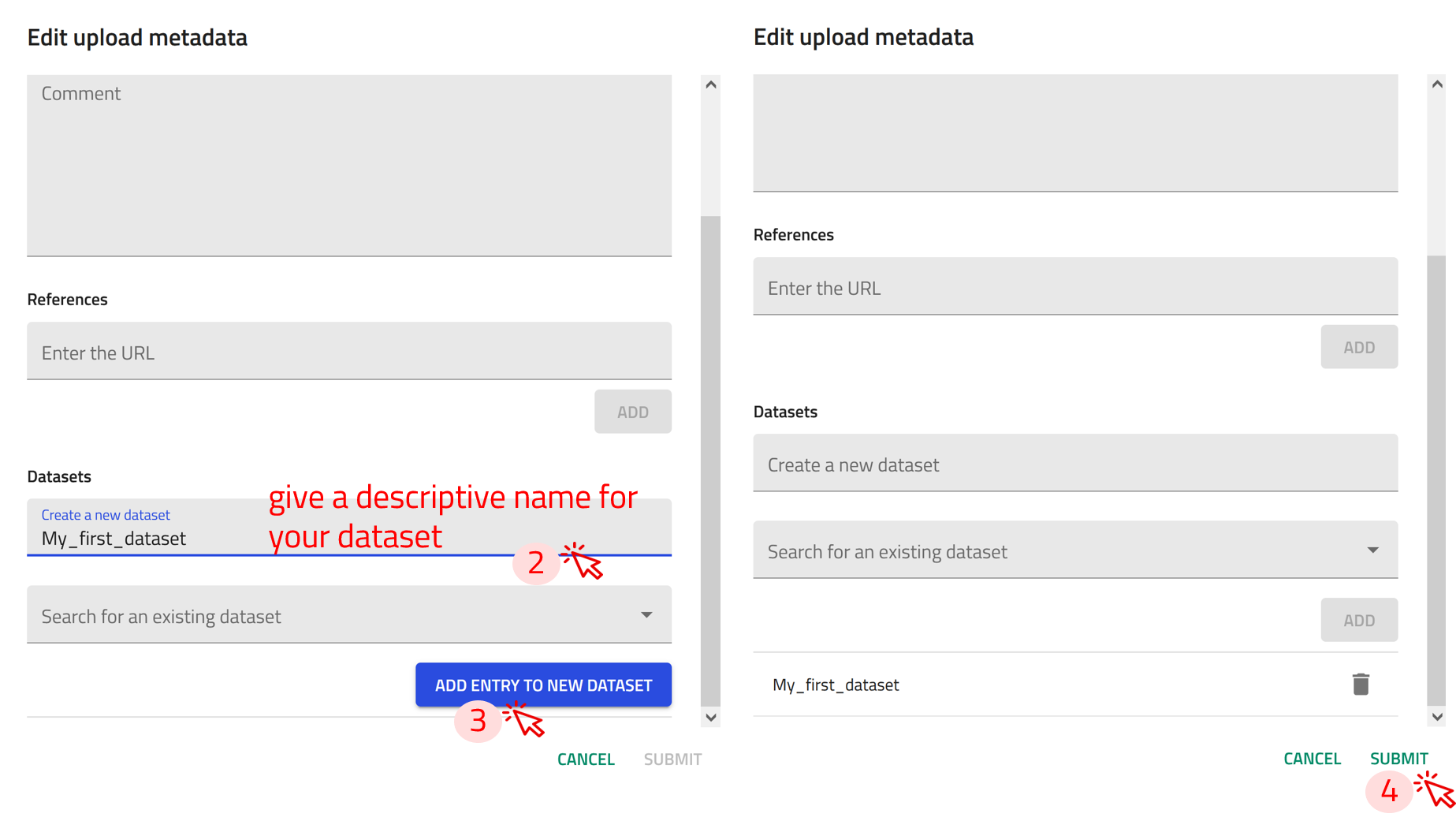
Step 2: In the Datasets section, you have two options:
- Create a new dataset: If the dataset you want to group your entries under doesn't exist yet, you can create one here.
- Search for an existing dataset: If the dataset already exists, you can search for it by name or other attributes.
Step 3: Once you've selected or created the appropriate dataset, click ADD ENTRY TO NEW DATASET
Step 4: Click on SUBMIT to group your entries under that dataset.
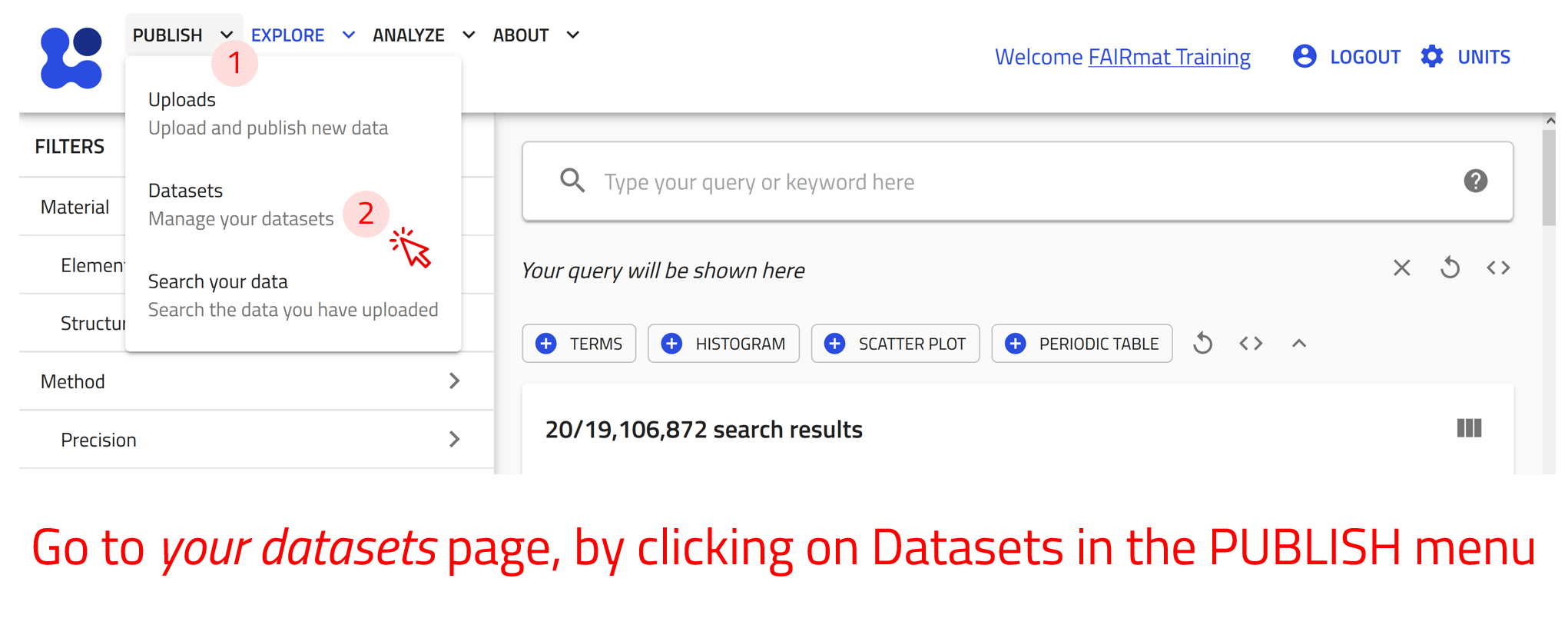
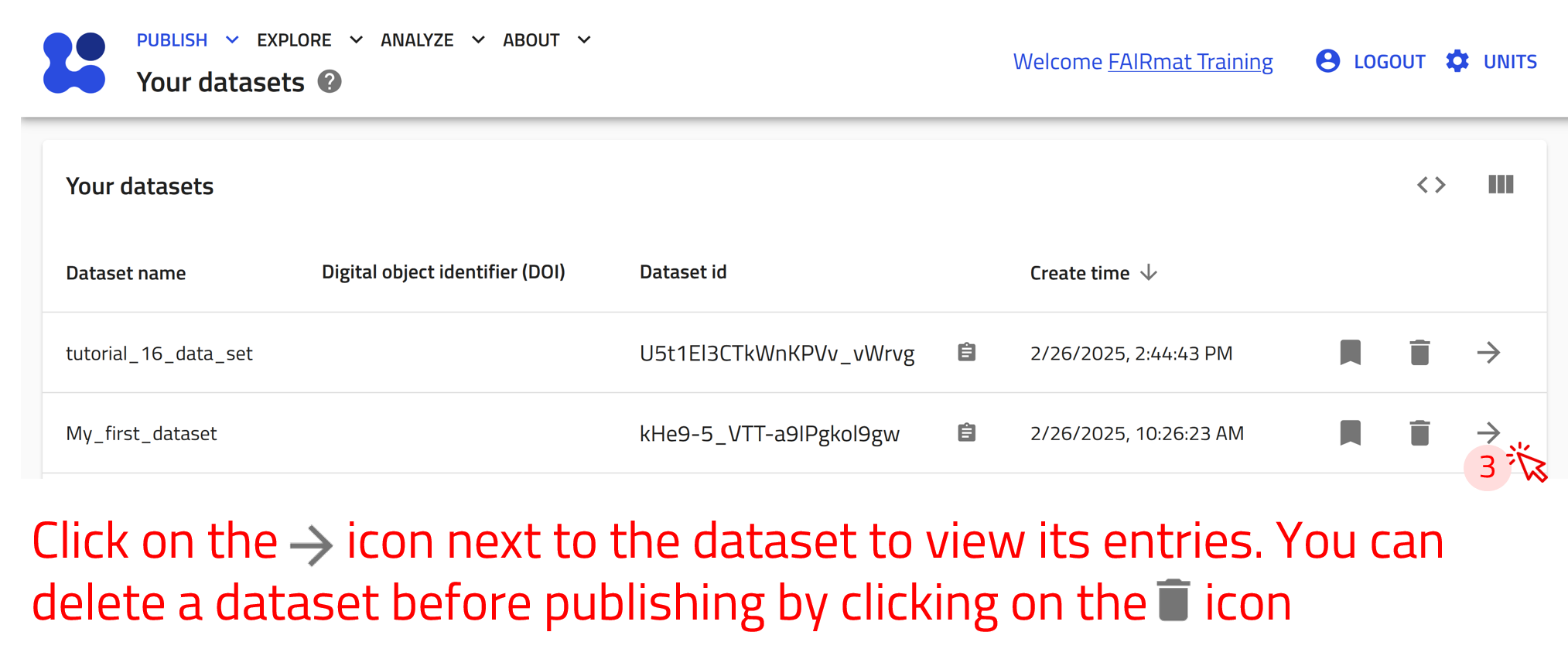
Manage a dataset and assign it a DOI¶
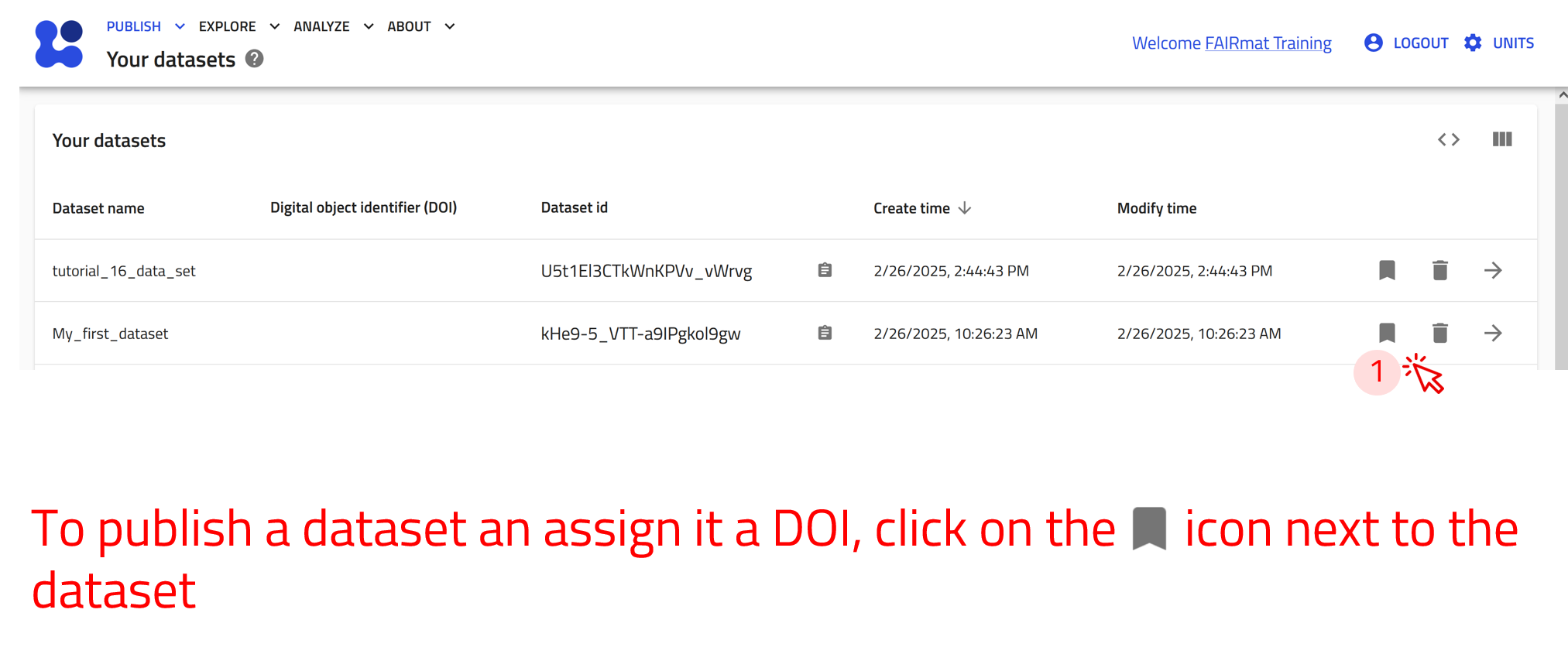
User-created datasets exist in the “Your datasets” page. You can reach there by clicking on Datasets in the PUBLISH menu. Here you can view a list of all your created datasets with their relevant information and assign them a DOI.
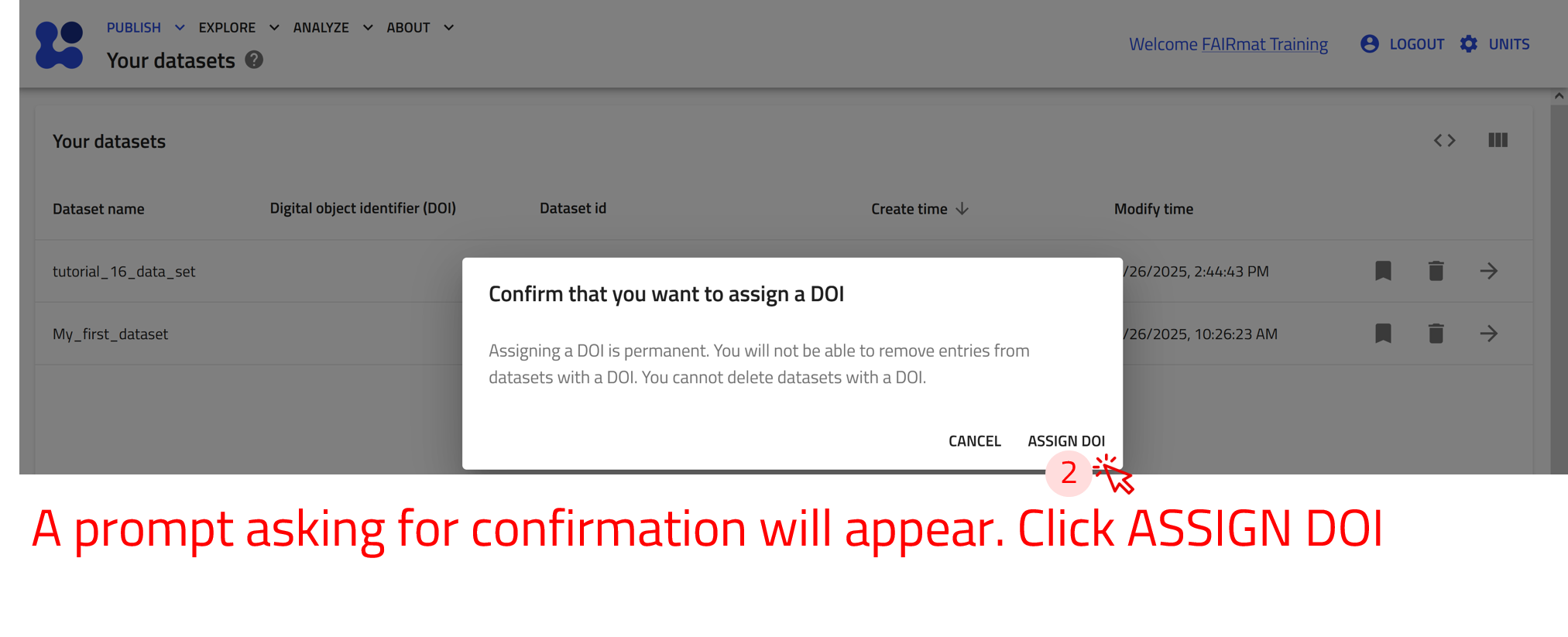
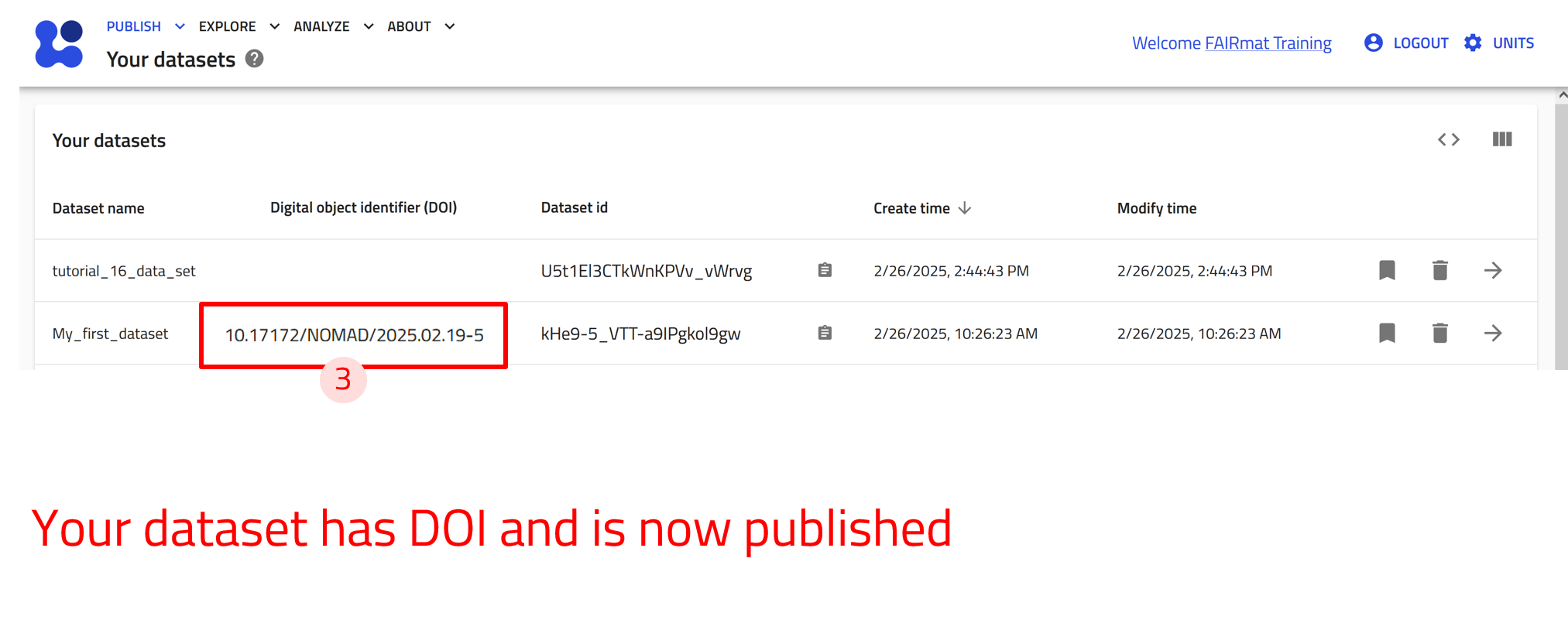
Assigning a DOI makes the dataset permanent—it cannot be modified or deleted.
If you want to test the process without actually publishing the data, you can do so in the NOMAD test installation.
Use the arrow buttons ⬅️➡️ below to follow the steps of exploring and managing your datasets.
Use the arrow buttons ⬅️➡️ below to see how to publish your datasets and assign them a DOI.